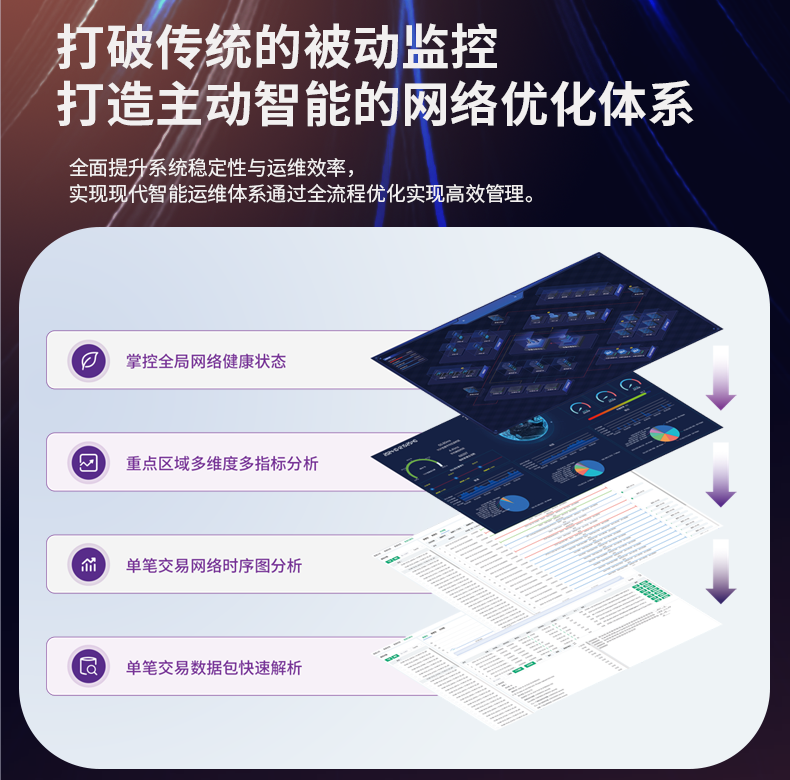
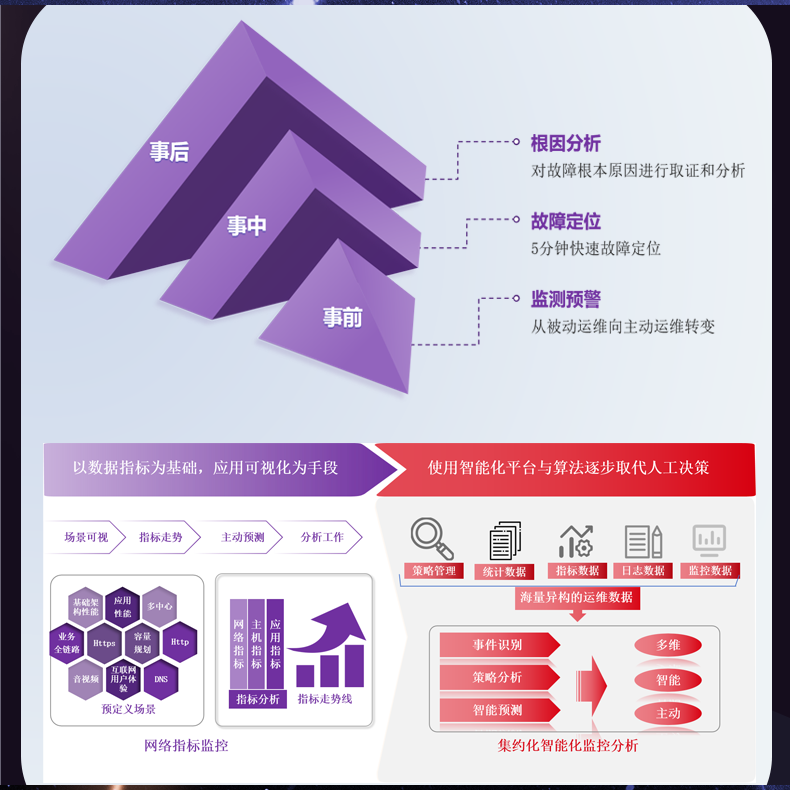
# 流量分析时,数据存储的容量和检索速度成瓶颈
在现代数字化浪潮中,流量分析已成为企业决策和优化业务流程的关键工具。然而,随着数据量的不断增加,许多企业在进行流量分析时面临着存储容量和检索速度的双重瓶颈。本文将详尽分析这些瓶颈的根源,并探讨潜在的解决方案,帮助企业更好地进行流量分析。
## 数据存储容量的挑战
### 1. 数据量的快速增长
随着互联网用户数量的急剧增加和物联网设备的普及,企业收集的数据量呈指数级增长。社交媒体、电子商务交易、传感器数据等都是数据爆炸的来源。因而,存储海量数据成为许多企业和组织的首要挑战。
### 2. 存储基础设施的限制
传统数据库和存储设备在处理大规模数据时往往捉襟见肘。随着数据量的膨胀,存储介质的容量需求也在不断增加。传统存储方案如关系型数据库在横向扩展方面存在固有的不足,需要投入大量成本进行电源、冷却和硬件扩展。
### 3. 数据类型的多样性
流量分析不仅仅涉及结构化数据,还包括大量的非结构化和半结构化数据(如文本、视频、图像等)。这种数据类型的多样性增加了存储复杂性,需要更为多样化的存储解决方案。
## 数据检索速度的瓶颈
### 1. 数量庞大的数据请求
面对庞大的数据集,数据检索的速度成为至关重要的因素。及时获取有价值的信息对于实时决策至关重要,但传统检索方法往往无法满足高并发以及低延迟的需求。
### 2. 数据整理和索引的复杂性
为了提高检索效率,企业需要对数据进行整理和索引,这一过程耗时且复杂。特别是在非结构化数据中,建立有效的索引以实现快速检索是一项艰巨的任务。
### 3. 网络带宽的限制
流量分析要求大量数据在网络中传输,这对网络带宽提出了极高的要求。尤其是当企业需要将数据从不同的物理位置传输到中央分析中心时,有限的带宽可能导致拖延和延迟。
## 解决方案与实践路径
### 1. 云存储和分布式存储系统
云存储提供了一种动态且高效的数据存储解决方案。使用AWS、Azure或Google Cloud等云服务,企业能够利用按需扩展的存储服务,以应对数据量的增长。结合分布式存储系统(如HDFS、Amazon S3)可以有效管理和处理大规模数据。
### 2. 采用NoSQL数据库
NoSQL数据库如MongoDB、Cassandra和Couchbase等在处理海量数据时表现出色。它们能够有效地存储非结构化和半结构化数据,并支持横向扩展。此外,NoSQL数据库通常具备较高的查询性能,能够满足低延迟的要求。
### 3. 实施大数据分析平台
使用Apache Hadoop、Spark等大数据平台,可以实现对大规模数据的快速分析和处理。尤其是Spark以其内存计算能力著称,能大幅度提高数据处理速度,并大大缩短检索时间。
### 4. 数据压缩与去重技术
通过实施数据压缩和去重算法,可以有效减少存储空间需求。采用如Snappy、Gzip等压缩工具可以在不丢失信息的情况下压缩数据,而去重技术可以消除重复数据,从而提升存储效率。
### 5. 边缘计算与CDN网络
在数据产生的边缘进行计算,可以减少数据的传输量,从而缓解带宽压力。边缘计算能够在接近数据源的地方处理数据,从而减少延迟。此外,利用内容分发网络(CDN),可以将数据分发到地理位置较近的服务器,进一步提高数据访问速度。
### 6. 人工智能和机器学习技术
利用人工智能和机器学习可以进行智能数据索引和检索,加快数据分析速度。通过训练模型进行模式识别和预测分析,可以在大量数据中快速找出关键业务信息。
## 结论
流量分析过程中,数据存储容量和检索速度的瓶颈,是企业在数字化转型中不可回避的挑战。然而,通过创新的技术手段,如云存储、NoSQL数据库、大数据平台、边缘计算等,企业可以有效突破瓶颈,提升流量分析效率。
企业必须根据自身需求和现有的技术环境,选择合适的解决方案。未来,随着技术的日新月异,数据存储和检索技术将继续演进,为流量分析提供更为高效的基础设施支持。面对数据快速增长的世界,积极适应技术变化不仅是应对挑战的最佳途径,也是把握机遇的关键。