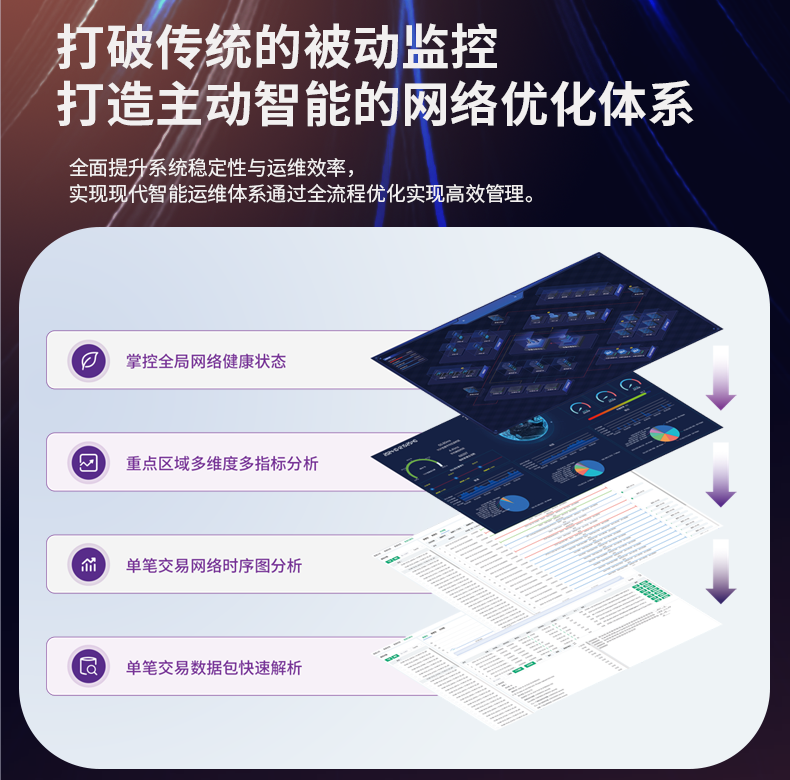
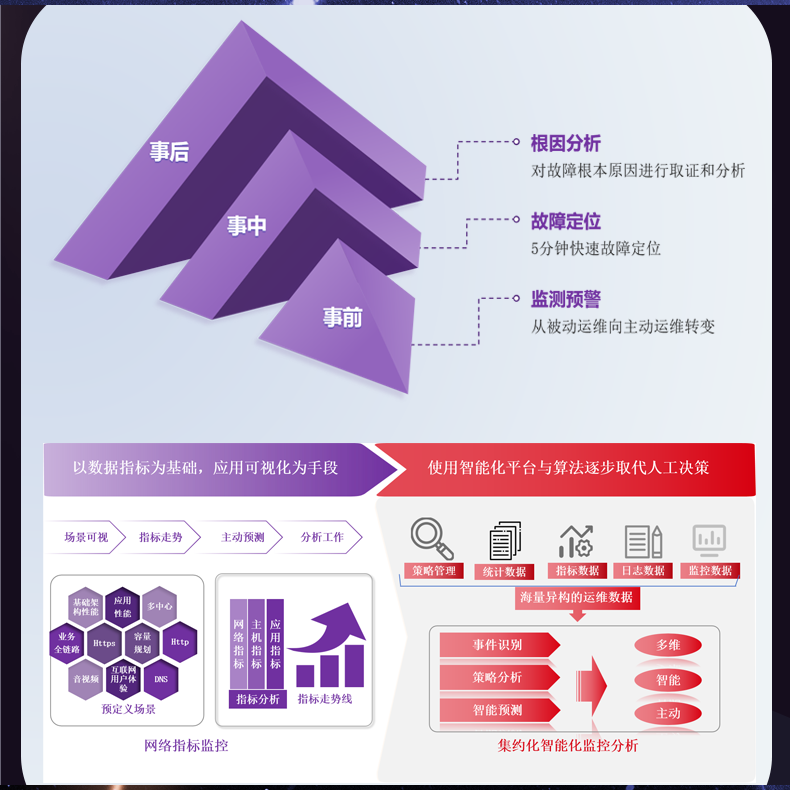
# 网络安全事件发生后,流量监控日志无法快速检索
在互联网快速发展的时代,网络安全事件频繁发生,给无数企业和用户带来了巨大的损失。然而,在响应这些事件时,一个常见的问题是:流量监控日志无法快速有效地进行检索。这不但延误了问题解决的时间,还可能导致更广泛的安全威胁。本文将对此问题进行深入分析,并提出合理的解决方案。
## 原因分析
### 数据量巨大
随着网络设备和技术的飞速发展,数据的产生速度早已超出我们的想象。据统计,一般企业每天生成的网络流量监控日志超过数TB之巨。数据如此庞大,给实时检索带来了极大的挑战。
### 日志格式复杂
网络流量监控日志的格式各异,通常包括来源IP、目标IP、传输的数据量等数十个参数。这种复杂性导致了检索困难,因为系统必须解析每个字段来完成查询。
### 缺乏良好的索引设计
许多企业没有在日志存储系统中实施有效的索引机制,这使得在大量数据中进行快速查询变得异常困难。无索引的大数据如同大海捞针,极大地拖慢了检索速度。
## 解决方案
### 优化数据存储架构
#### 使用分布式文件系统
首先,企业应考虑引入分布式文件系统(如HDFS)来处理大量的流量日志数据。这种系统不仅可以横向扩展,还提供了一种可靠的冗余机制,以确保数据的安全性和可用性。
#### 数据压缩和拆分
将日志数据进行压缩和拆分存储,可以大幅度降低存储成本。这种方式还能提高数据检索的效率,尤其是在压缩算法的支持下,减少I/O操作时间。
### 建立高效的日志索引
#### 倒排索引技术
启用倒排索引是提高日志检索速度的关键。倒排索引允许通过记录内容快速找到对应的日志条目,而无需遍历所有数据。这种方法早已在搜索引擎中得到验证。
#### 定期优化和维护索引
高效的索引不仅在于创建,还需要定期优化和维护。清理无效数据、合并小索引、重新排列索引结构都能显著提升速度。
### 引进实时流处理
#### Apache Kafka集成
通过使用Apache Kafka这种高吞吐量的消息代理,企业可以进行实时日志流处理。将监控数据流式传输到分析系统中,而不是等到积累到一定量才处理,可以提高实时性。
#### 使用流处理框架
引入Apache Flink或Apache Storm等流处理框架,可以进行实时数据的处理和分析,支持快速查询和告警。这样的系统不仅提高了处理能力,还能更早地发现潜在问题。
### 提高检索工具的智能化
#### AI驱动的日志解析
利用AI技术,特别是自然语言处理(NLP)技术,自动解析和识别日志内容中的关键异常信息。这种智能分析可以将大量基础性检索任务自动化,从而提升效率。
#### 自适应查询优化
基于历史记录和用户行为,使用机器学习模型进行自适应查询优化。通过分析查询规律和日志特征,调整索引优先级和缓存策略,大幅度减少检索时间。
## 案例分析
### 某金融行业的实践
一家大型银行实施了上述方法后,将其流量日志检索时间从原来的几小时缩短到了几分钟。具体措施包括:在HDFS上进行分布式存储,应用倒排索引技术,使用Kafka进行日志流管理,并结合机器学习优化检索策略。该银行的数据安全团队报告,响应安全事件的效率提高了60%。
### IT企业的经验
一家大型的IT公司在使用Elasticsearch这一工具进行日志检索时,遇到系统性能瓶颈问题。在引入倒排索引和实时流处理后,该公司将检索速度提高了两倍,同时减少了CPU和内存使用率。加强的AI分析模型使得他们能在数据采集的瞬间快速响应至关重要的安全警报。
## 结论
在网络安全事件日益严峻的背景下,提高流量监控日志的检索速度无疑是一项挑战性任务。然而,正如本文所述,通过优化数据存储结构、合理建立索引系统、采用实时流处理和提升智能检索工具,企业可以有效地提高响应时间,进而增强其安全防范能力。
网络安全不容忽视,快速和高效的日志检索是保障安全的第一步。企业必须重视这一环节,并根据自身需求和业务特点进行调整和优化。只有这样,才能在复杂多变的网络环境中立于不败之地。