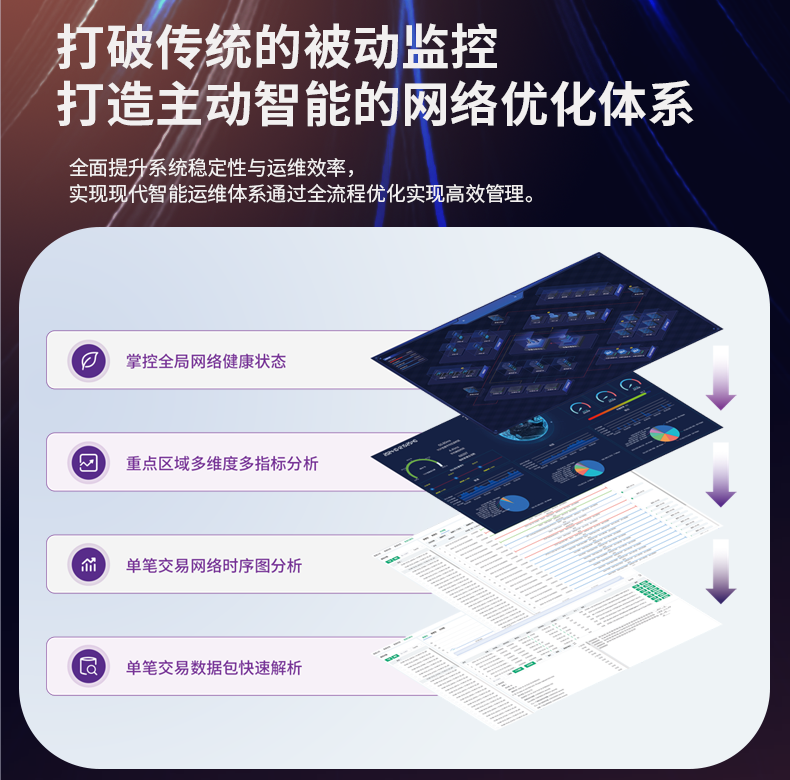
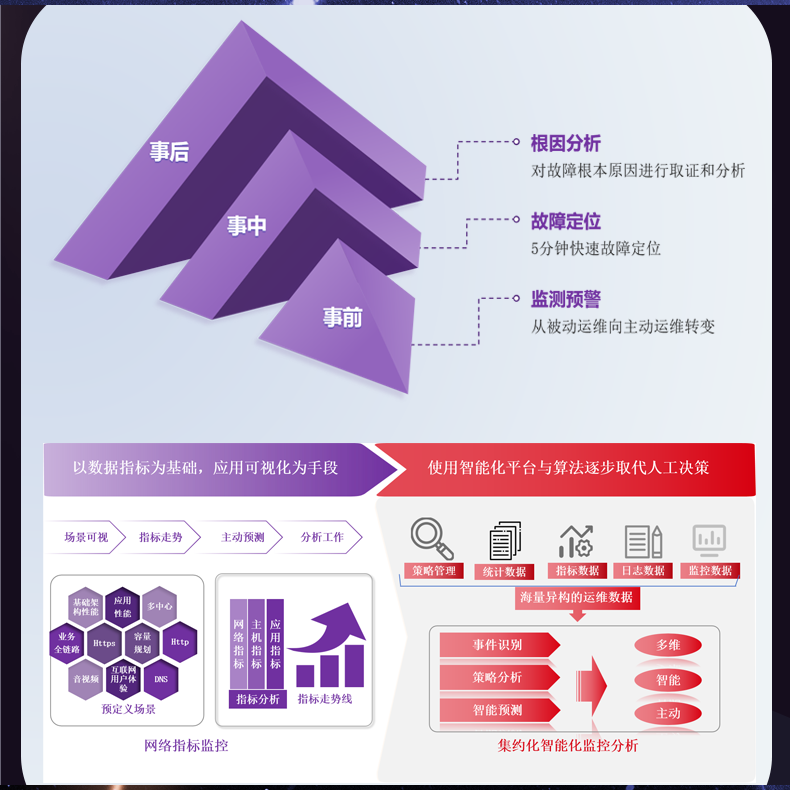
# 流量数据存储和处理存在瓶颈,无法满足需求
现代信息时代,由于互联网、物联网及各种智能设备的普及,每天产生海量流量数据。这些数据不仅规模庞大且复杂多样,传统的数据存储与处理系统逐渐暴露出瓶颈。本文将详细分析这一问题,同时探讨行之有效的解决方案,以期为读者提供深入的理解与实用的参考。
## 流量数据增长的压力
### 数据规模的急剧膨胀
随着数字化转型的加速,数据的生成速度和复杂程度正在以前所未有的速度增长。企业需要处理的不仅是传统的结构化数据,还包括大量的非结构化数据和半结构化数据(例如图像、视频、传感器数据等)。这些数据的激增给存储和处理系统带来了巨大的压力。
### 数据类型的多样性
不同业务场景下的数据类型日益复杂,例如社交媒体平台处理文本、图像和视频数据,智能制造系统处理来自传感器的实时流量数据。因此,存储和处理流量数据不仅需要应对数量上的增加,还需能支持类型多样的数据。
### 实时处理的高要求
流量数据不仅规模庞大,且处理实时性需求很高。在许多场景中,决策需要依赖于实时数据的快速分析,例如金融交易系统中的高频交易、智能交通中的实时导航。传统批处理系统无法满足实时数据处理需求,导致许多企业在数据利用上处于劣势。
## 存储和处理的瓶颈分析
### 存储容量的限制
传统存储系统设计时,未能预见当今数据爆炸的态势。硬件成本和物理空间限制了存储容量的扩展。此外,公司广泛使用的关系型数据库因其结构化存储方式,在处理非结构化数据时效率较低,减少了存储系统的灵活性。
### 处理速度的不足
数据处理瓶颈不仅体现在存储能力上,还在速度上。传统数据处理方式主要依赖批处理,无法有效应对实时数据流。随着数据量急剧增加,处理速度不足的弊端更为显著,导致数据决策的时效性和准确性受到影响。
### 数据管理的复杂性
管理庞大的数据集要求高效的索引、检索以及备份和恢复系统。在大规模流量数据处理中,传统的数据管理和维护技术已经难以高效应对,随着数据的不断流动和变化,数据管理复杂性进一步增加。
## 解决方案的探讨
### 大数据技术引领存储革命
#### 采用分布式存储系统
分布式存储系统作为应对大数据挑战的核心技术之一,弥补了传统系统存储容量和性能上的不足。通过网络集群和数据分片,将数据存储的压力分散到多个节点上。例如Apache Hadoop的HDFS系统能够高效存储和管理海量非结构化数据。
#### 云存储与混合解决方案
云存储的弹性扩展特性使其成为流量数据存储的理想选择。以AWS S3和Azure Blob为代表的云存储解决方案可以按需提供存储容量,允许企业根据数据增长灵活扩展存储资源。同时,采用混合云解决方案可以结合本地和云资源,优化存储效率与成本。
### 优化实时数据处理
#### 实时流处理技术
实时流处理技术如Apache Kafka和Apache Flink能够在数据生成的同时进行处理和分析。这些技术采用分布式计算架构,能够确保高效的数据流动和实时决策支持,满足高频交易和智能监控等场景的需求。
#### 数据湖和数据仓库整合
数据湖和数据仓库的结合进一步强化了实时数据分析能力。数据湖用于低成本存放大量原始数据,而数据仓库则用于结构化存储和快速查询分析。通过这两者的协同,可以实现对数据的高效管理和实时洞察。
### 简化数据管理与提升可用性
#### 自动化数据管理工具
引入自动化数据管理工具能够显著简化流量数据管理过程。工具如TensorFlow Extended (TFX) 或 Kubeflow Pipelines不仅能自动化数据流监控和任务调度,还能提高数据处理效率和系统可靠性。
#### 数据治理框架
采用完备的数据治理框架保障数据质量和合规性至关重要。通过设置数据权限、数据标准和变更日志,可以实现数据的安全管理与合规使用。同时使用智能的数据清洗和整合工具能够确保流量数据的高质量和可用性。
## 总结
流量数据存储和处理存在瓶颈问题,已成为企业信息化升级过程中亟待解决的重大课题。通过采用分布式存储系统、实时流处理技术、自动化数据管理工具等解决方案,企业可以突破传统技术限制,实现对海量流量数据的高效利用,增强竞争力并推动业务持续发展。
这一领域的技术仍在快速进步,未来更多创新将不断涌现,不论是对存储容量的突破或是处理速度的优化,都将进一步推动流量数据利用的变革。希望本文提供的分析与解决方案能为企业在面对数据挑战时,提供值得参考的思路。
关于流量数据存储与处理的瓶颈问题及其解决方案探讨,您是否有其他见解或实践经验?欢迎在评论区分享!