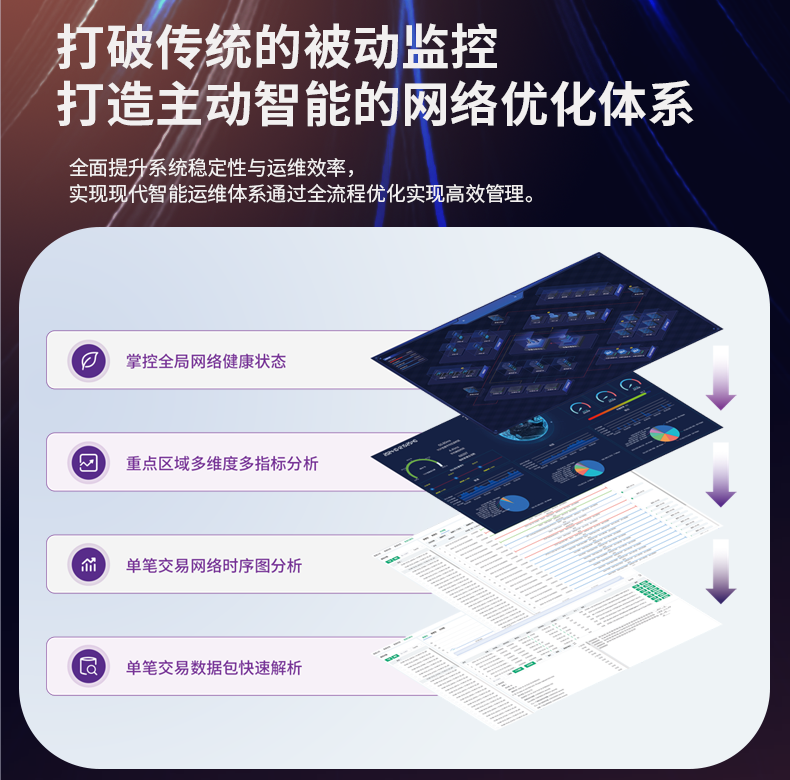
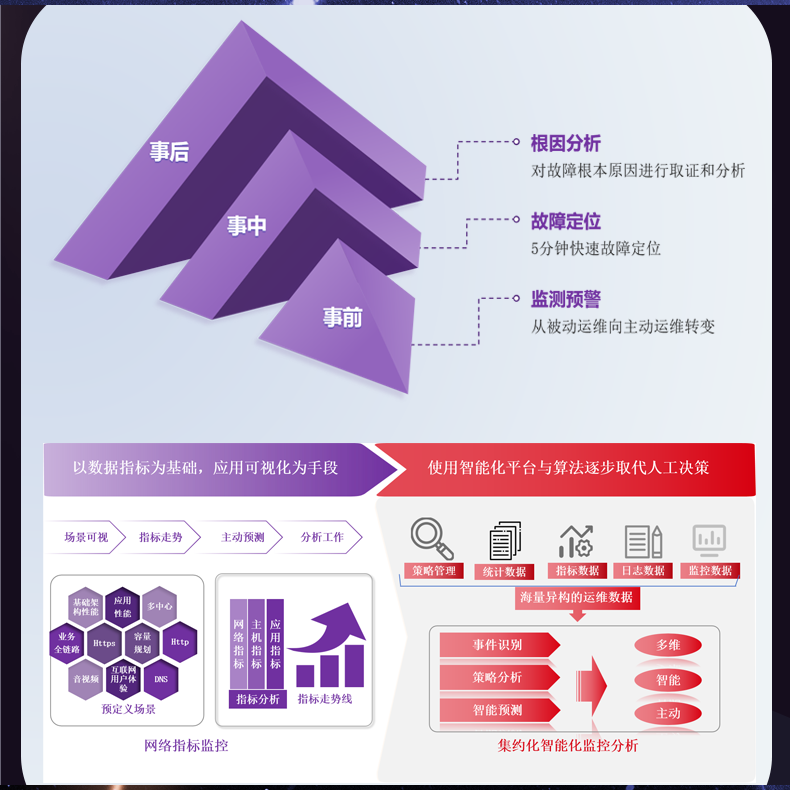
# 流量日志存储系统无法处理超大规模数据的查询需求
在当今互联网环境下,流量日志存储系统已成为企业和组织的重要数据工具,用于监控网络活动、分析用户行为及安全审计。然而,当系统面临超大规模的数据集时,传统的流量日志存储系统往往无法高效处理查询请求,从而影响业务决策。本文旨在分析此问题的成因,并提出切实可行的解决方案。
## 一、流量日志存储系统现状与挑战
流量日志存储系统用于记录和查询流经网络的所有数据。它的典型应用包括网络性能监控、安全事件调查以及流量预测。然而,随着网络规模迅速增长和数据量的爆炸式增加,传统的日志存储系统面临严峻挑战。
### 1. 数据量的爆炸性增长
随着互联网接入设备和传输的数据流量数量的激增,产生的日志数据也呈现爆炸性增长。以大型互联网公司为例,其流量日志产生速率可高达每秒数十TB。这种规模的数据对存储和查询提出了极高的要求,传统的数据库系统难以承受。
### 2. 查询性能瓶颈
传统日志系统通常基于关系型数据库,虽然其在处理结构化数据时具有强大能力,但当数据规模达到PB级别甚至更多时,查询性能出现严重瓶颈。一旦数据入库,复杂的查询操作会导致大量索引遍历和I/O操作,延迟增加,用户体验下降。
### 3. 存储成本与管理难度
大规模数据的存储不仅需要昂贵的存储设备,还需要专业的管理与维护。存储成本变得难以控制,而保障数据完整性与访问性能使得管理复杂度提高。
## 二、需求分析:何为“超大规模”查询需求?
在探讨解决方案之前,我们需明确“超大规模”查询需求主要包括:
### 1. 实时性
用户或管理员希望能够实时访问或分析日志数据,以便快速做出反应。尤其在安全领域,实时性是检测和遏制攻击的重要指标。
### 2. 灵活性
无需预先定义严格的数据模式,用户可以灵活地执行各种不同维度和粒度的查询。系统需支持多种查询类型,如过滤、聚合、化简等。
### 3. 高并发
支持多个用户同时发起复杂的查询请求,而不降低系统响应速度,是一个系统必须面对的显著挑战。
## 三、解决方案:向可扩展架构与高效技术迈进
为了解决超大规模数据查询的需求,各类新技术和系统架构仍需得到应用和优化。
### 1. 大数据技术的引入
#### Hadoop及其生态系统
Hadoop作为分布式存储和处理解决方案,能很好地处理大数据量环境。其HDFS系统提供可靠的存储,而MapReduce等编程模型简化了大规模数据集的处理。
#### Spark与流计算
与Hadoop相比,Apache Spark提供了更快的内存计算能力,适合需要更高吞吐和灵活性的任务。结合Spark Streaming可支持实时数据处理,为流日志查询提供了优质解决方案。
### 2. 列式存储与压缩
在大规模数据场景中,使用列式存储(如Apache Parquet或Apache ORC)和数据压缩(如Snappy、Gzip)可以显著提高查询性能。
### 3. 使用NoSQL数据库
NoSQL数据库如Cassandra、Elasticsearch和MongoDB在数据结构灵活性和扩展性上具有独特优势。它们更适合处理非结构化或者半结构化的流量日志数据,支持快速写入和全文检索能力。
### 4. 强化索引和多层次缓存
通过引入如LSM树(Log-Structured Merge-Tree)和B树进行优化索引,同时应用内存缓存和分布式缓存(如Redis、Memcached)来减少磁盘I/O,优化查询速度。
## 四、应对存储与管理的规则与策略
### 1. 数据分区与生命周期管理
有效的数据分区策略可以减少单个查询的处理负担,而数据生命周期管理策略则能帮助自动化地处理旧数据,释放存储空间以供新增数据使用。
### 2. 安全与访问控制
在无缝处理海量数据之余,保障数据的安全性与合规性不容忽视。应部署严格的访问控制机制,确保只有被授权的人员能够访问关键信息。
### 3. 自动化运维与监控
借助自动化工具(如Ansible、Kubernetes)进行运维和监控(如Grafana、Prometheus)可减少人为操作失误,并及时检测和改进系统性能瓶颈。
## 五、未来展望与总结
大规模数据处理是个动态发展的领域,围绕这一挑战,还有许多技术和方法等待探索与验证。为维护高效的流量日志存储和查询系统,企业需要持续评估和调整其数据库和存储策略,主动应用新兴技术。
此主题的探索不仅需要技术上的革新,还需管理者的全面理解。我们相信,通过不断推进技术方案和实践应用,能够更好地满足不断增长的企业和用户的需求,使数据存储系统从容应对海量日志数据的挑战,变得更快、更稳定、更具扩展性。