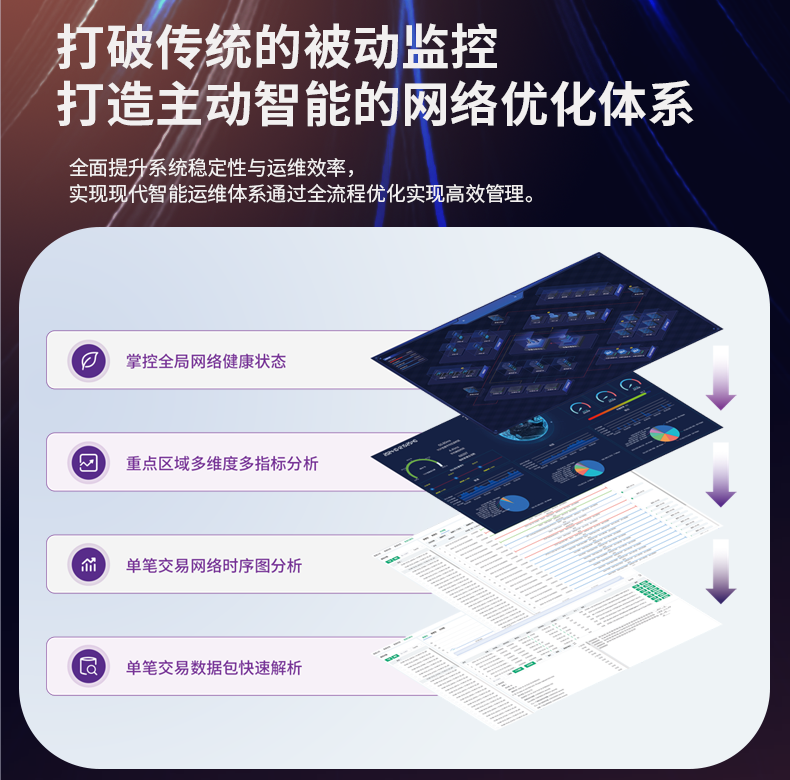
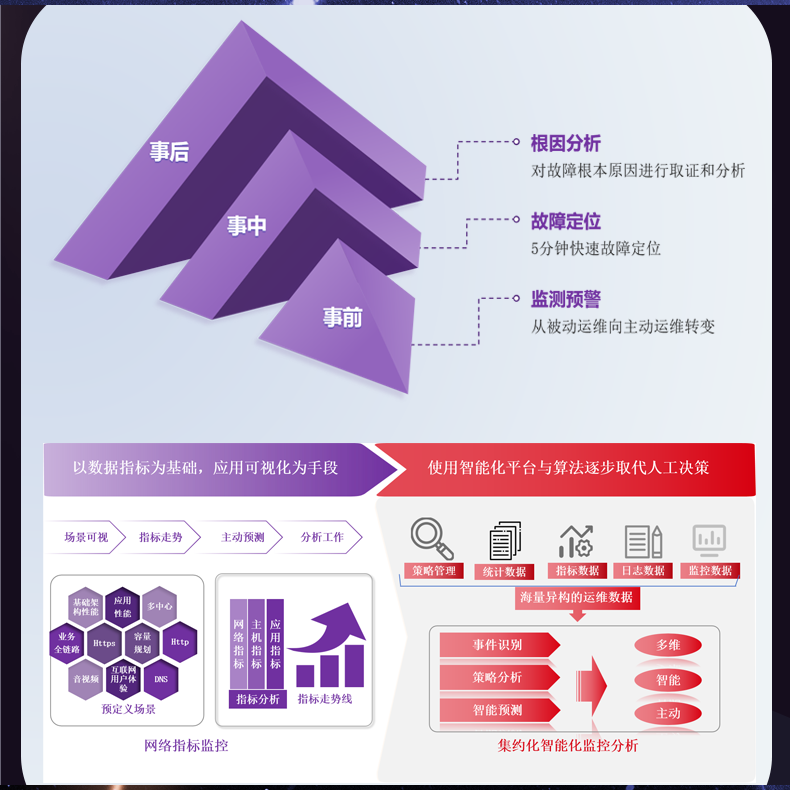
# 流量分析过程中,无法有效过滤不相关的数据
在当今的数字化时代,流量分析是企业和组织理解用户行为、优化运营过程的重要工具。然而,流量分析过程中,常常面临一个棘手的问题:如何有效过滤不相关的数据。无效数据的混入不仅可能导致误导性结论,还可能影响决策的准确性和业务的成功运营。在这篇文章中,我们将深入探讨这一问题,并提供详实的解决方案。
## 一、数据流量分析的背景与挑战
### 1.1 数据流量分析的重要性
在数字化环境中,流量分析能够帮助企业和组织了解用户行为模式、趋势以及互动情况。这些分析不仅有助于提高用户体验,还能为市场营销策略、销售策略提供依据。然而,分析过程中遇到的不相关数据极大地影响了其有效性。
### 1.2 不相关数据的定义
不相关数据指那些与分析目标无关或噪声成分较大的数据。例如,来自机器人程序生成的流量、误导来源(如广告点击欺诈)、偶然的点击以及与目标市场无关的用户行为等。这些数据会在分析过程中引入误差,导致结果失真。
### 1.3 面临的挑战
1. **数据量大且复杂**:大数据环境中,数据源多样、类型复杂,手动排查显得不切实际。
2. **实时性要求高**:对流量的实时分析需求使得快速而有效的数据过滤变得困难。
3. **技术手段的局限**:现有的过滤工具和方法可能无法识别所有类型的不相关数据。
## 二、不相关数据给流量分析带来的影响
### 2.1 减少分析结果的准确性
不相关数据的混入会导致分析结果偏离真实用户行为,导致策略错误。例如,误判某个广告的点击率,可能会增加不必要的广告支出。
### 2.2 资源浪费
处理和存储不相关数据会消耗大量的计算资源和存储空间,增加运营成本。
### 2.3 决策失误
基于不准确的数据进行决策可能会带来诸如市场策略失误、客户流失等不良后果,从而直接影响企业的盈利能力。
## 三、不相关数据来源的识别与分类
### 3.1 识别不相关数据来源
1. **自动化流量**:如爬虫、机器人的访问,需要通过用户代理、访问模式等进行识别。
2. **地理位置偏差**:与业务无关的地域流量,通常通过IP地址进行识别。
3. **意外来源**:误点击产生的流量,难以和真实点击区分,需要结合点击行为分析。
### 3.2 不相关数据分类
1. **技术性噪声**:如网络延迟产生的重复请求。
2. **人为误导**:如点击欺诈和刷流量行为。
3. **系统错误**:如来自于错误集成或数据导入的无效信息。
## 四、基于先进技术的解决方案
### 4.1 使用机器学习进行流量过滤
1. **模式识别**:利用机器学习算法识别异常数据模式。
2. **行为分析**:分析用户的交互行为,识别正常与异常流量。
3. **自我学习**:机器学习模型可以通过不断更新数据生成更精准的过滤规则。
### 4.2 基于规则的智能过滤
1. **IP和地理位置过滤**:创建黑白名单,过滤掉不相关地区的IP流量。
2. **用户行为规则**:设定行为特征规则,例如跳出率、页面停留时间等指标。
3. **设备和来源筛选**:利用设备信息和来源渠道过滤掉不相关数据。
### 4.3 实时监控与报警系统
1. **异常检测**:通过实时监控识别流量异常并发出警报。
2. **快速响应机制**:在发现异常流量后,能迅速作出反应,调整数据过滤策略。
### 4.4 数据清理与转换
1. **数据去重**:清理重复数据以保持分析数据的纯净性。
2. **格式规范化**:统一数据格式,为后续分析提供便利。
3. **无效数据剔除**:根据规则或模型自动化去除噪音数据。
## 五、有效流量分析策略的实施
### 5.1 评估与监测计划
建立持续的评估机制,监控数据过滤的效果,不断优化规则或算法,以适应不断变化的流量特征。
### 5.2 技术与人力结合
技术手段在过滤不相关数据中起重要作用,但始终需要人员对工具和方法进行监控和调整。
### 5.3 定期回顾与更新
定期回顾数据策略的有效性,并根据市场和业务的变化调整过滤规则和算法模型。
## 六、结论
有效过滤不相关的数据,对于提升流量分析的准确性和决策的科学性至关重要。通过明确识别问题、采用先进技术和制定合理策略,企业能更好地利用其数据资源,提高市场竞争力。在快速变化的数字世界中,只有不断学习和适应,才能在数据驱动的决策中立于不败之地。