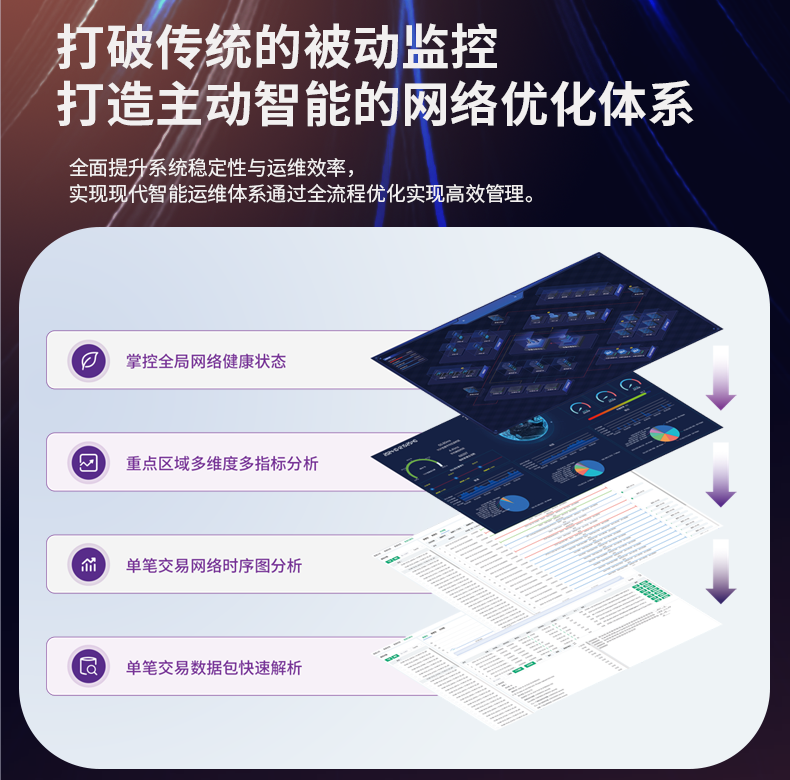
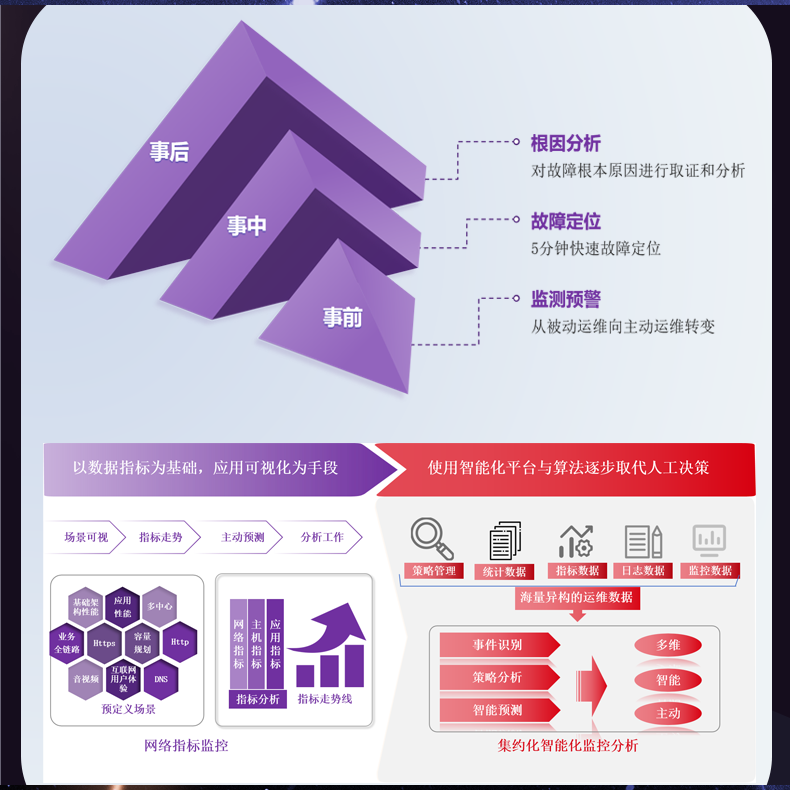
# 传统流量监控工具未能适应高速、大规模数据流量的变化
在当今这个日益数字化的时代,数据无处不在。无论是在金融、医疗还是电子商务等领域,数据流量的管理和监控都至关重要。然而,随着互联网的快速发展和大数据的兴起,传统的流量监控工具在应对高速、大规模的数据流量变化方面渐显不足。本文将深入探讨这一问题,并提出有效的解决方案,以帮助企业和组织适应新的数据流量动态。
## 一、传统流量监控工具的局限性
### 1.1 静态阈值与动态环境的矛盾
传统流量监控工具大多依赖于静态阈值设定来检测异常流量。这种方法在数据流量较为稳定的环境下或许有效,但在当今变幻莫测的网络环境中,预先设定的静态阈值难以及时调整应对动态变化的数据流量。这种矛盾导致了监控工具不能有效识别真正的异常流量,误报率高,严重影响其可靠性。
### 1.2 缺乏实时性的数据处理能力
现代化网络对实时性要求越来越高,而传统流量监控工具通常在采集、分析以及报警等环节上反应迟缓,难以提供决策所需的即时洞察。这一短板在金融交易和在线服务等对时效要求极高的场景中尤为明显。
### 1.3 扩展性不足
另外,传统流量监控工具往往以单机部署为主,其处理能力受限于单一硬件的性能。随着流量规模的扩大和数据复杂性的增加,传统工具在扩展性上的不足愈加显著,难以应对多元化的大数据环境。
## 二、现代数据环境对流量监控的要求
### 2.1 高速数据处理能力
在互联网飞速发展和数据量爆炸式增长的驱动下,监控工具需要能够处理更高速度、更加海量的数据。这就要求系统具有更高的吞吐量和更低的延迟,以应对流量的突然激增和大规模请求。
### 2.2 多维度数据分析
现代数据流量不仅仅体现为简单的请求数量,还包括复杂的用户行为分析、协议使用、地理位置等多维度信息。监控工具必须支持更全面的数据分析能力,以从繁杂的数据中挖掘出有意义的信息。
### 2.3 自适应能力
网络环境的动态变化要求流量监控工具能够根据流量模式的变化自动调节监控策略。自适应能力包括智能报警和自动调整检测参数,以及时应对异常状况。
## 三、解决方案:现代化的流量监控工具
### 3.1 使用分布式架构
为了适应大规模数据流量,现代流量监控工具可以借助分布式架构,实现高扩展性和高可用性。分布式系统通过跨多台服务器处理数据,能显著提高系统的处理能力和容错性。Apache Kafka、Flink等工具成为支持高并发数据流处理的利器。
### 3.2 引入机器学习算法
机器学习在流量监控中的应用可以帮助系统更精准地识别异常流量和趋势预测。通过训练模型,系统能够根据历史数据自适应设置报警阈值,并识别新出现的攻击模式。例如,可以使用集成学习方法来提高异常检测的准确性。
### 3.3 提升实时数据处理能力
为了提高实时处理能力,可以在监控系统中加入流处理技术,使数据在流动过程中就能被处理和分析。这样的设计能确保决策的实时性,避免因延迟造成的信息滞后。Apache Flink是流处理领域的优秀代表之一。
### 3.4 实现可视化和智能报表
数据可视化技术的应用,使技术团队能够清晰、直观地掌握流量变化情况。通过图表和数据可视化面板,系统能够自动生成智能报表,并根据不同用户需求进行自定义展示,这对于决策层来说尤为重要。
## 四、实施现代流量监控策略的挑战
### 4.1 成本与技术投入
引入新型流量监控系统需要企业在软硬件基础设施上进行大量投资。同时,培训员工掌握新工具和技术也需投入额外的时间与资源。
### 4.2 数据安全与隐私
在处理高速、大规模的流量数据时,如何保障数据的安全和用户隐私也成为一大挑战。公司需要制定和遵守严格的数据治理政策,以确保数据的安全性和合规性。
### 4.3 复杂系统的运维
现代化的流量监控系统往往由多种技术整合而成,系统的复杂性增加了运维的难度。团队需要具备多方面的技术能力才能有效进行系统维护和问题排查。
## 五、结论
随着数据流量的不断增长和复杂性的提高,传统流量监控工具面临重大挑战。采用现代化流量监控工具和策略是应对这一变化的必然选择。通过分布式架构、机器学习和流处理技术的结合,企业可以更好地适应高速、大规模的数据流量变化。同时,必须注意实施过程中可能面临的挑战,合理管理成本、确保数据安全并提升团队技术能力。通过不断迭代和进步,新的流量监控系统必将更好地服务于未来的数字化发展。