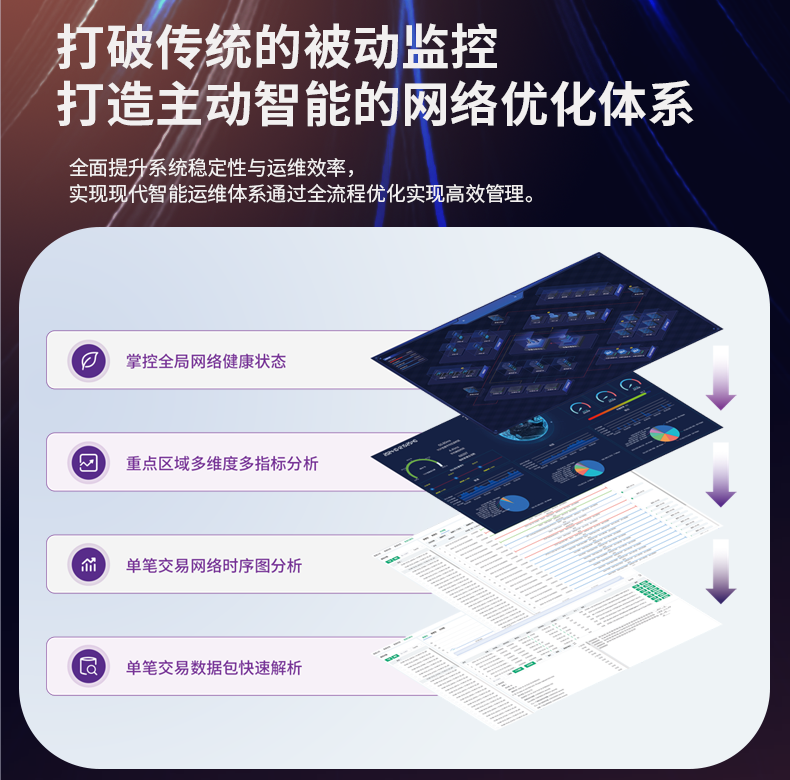
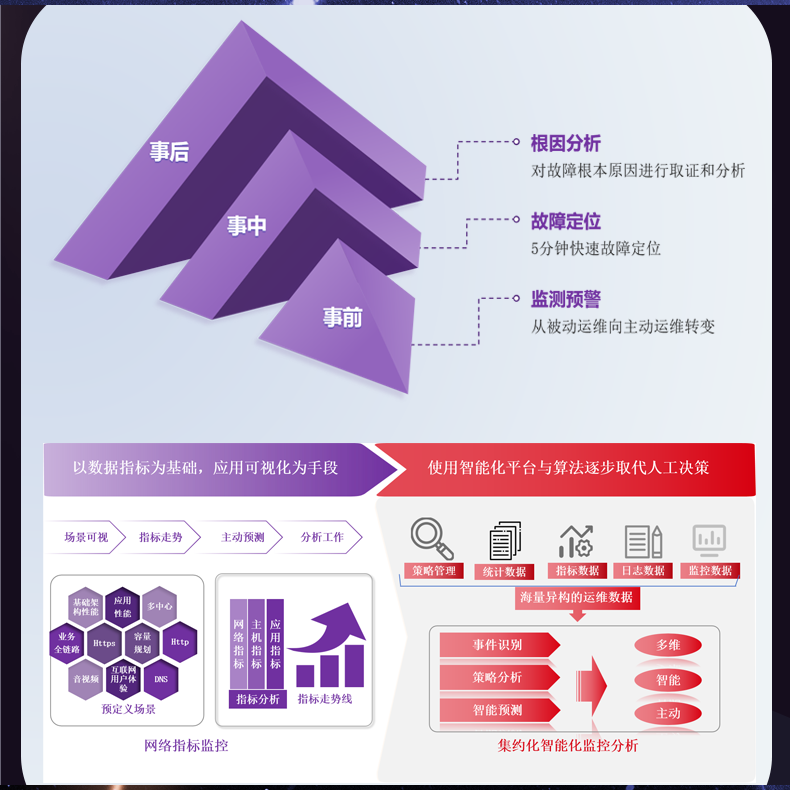
# 大规模网络中流量分析的实时性差
在当今数字化时代,网络流量分析已经成为保障网络安全和性能优化的重要手段。然而,面对大规模网络环境,实时分析流量的能力却面临着严峻挑战。本篇文章将深入探讨网络流量分析中的实时性问题,并提出详实的解决方案来应对这些挑战。
## 网络流量分析实时性差的原因
### 1. 数据流量量大
随着互联网用户的剧增和物联网设备的广泛应用,网络流量的规模也在急剧增长。大规模网络产生了海量的数据包,这使得实时处理变得异常困难。传统的分析工具在处理如此海量的数据时,经常会出现计算瓶颈,无法保证实时性。
### 2. 分析算法复杂性
为了识别和分类各种复杂的网络流量,分析算法变得愈加复杂。这些算法需要快速并准确地检测异常流量、分辨服务类型、识别用户行为等。然而,复杂度的提升必然导致算法执行时间变长,从而影响实时性能。
### 3. 数据存储延迟
在流量分析过程中,数据存储是一个必不可少的环节。然而,由于大规模网络流量的持续增长,传统存储系统在写入速度和检索速度上难以满足实时分析需求。这种延迟性进一步拖慢了整体分析的实时性。
### 4. 网络拓扑变化频繁
大规模网络中,拓扑结构常常会发生变化,如设备的加入和移除、网络路径的中断与切换等。这增加了实时追踪和分析的难度,令问题更加复杂。
## 解决网络流量分析实时性差的问题
### 1. 高效的流处理引擎
高效的流处理引擎能够在数据生成时立即进行处理,这样就减少了时延,提升了实时性。例如,Apache Kafka 和 Apache Flink 是典型的分布式流处理框架,能够以极高的吞吐量和低延迟来处理大规模数据。
#### 优点:
- 分布式架构允许横向扩展
- 提供可靠的数据处理保证(如精准的一次分发)
- 对于数据流的实时操作能力强大
### 2. 使用机器学习优化分析算法
通过引入机器学习和深度学习技术,网络流量分析可以显著提高实时性。机器学习算法可以适应不同的流量模式动态地优化,并能够进行异常检测,从而减少细粒度分析的时间成本。
#### 应用场景:
- 异常检测:如DDoS攻击和网络入侵检测
- 流量分类:自动识别流量类型
- 用户行为分析:基于模式识别预测未来行为
### 3. 基于边缘计算的架构
边缘计算将计算资源下沉到靠近数据生成的边缘设备。这样可以在靠近数据源处进行快速的数据预处理和初步分析,减少中心服务器的负担并加快响应速度。
#### 解决方案示例:
- 部署边缘设备,使用轻量级的处理算法进行数据过滤和预处理
- 保留关键数据供进一步分析,将不必要的数据丢弃
### 4. 存储与检索的优化
为了克服数据存储延迟,可以采用新型存储技术,如NoSQL数据库、内存数据库(如Redis)、以及对象存储来提高存取速度。此外,压缩技术也可用于减少数据量,提高传输效率。
#### 存储策略:
- 使用分布式数据库以提高可扩展性
- 采用异步写入和写缓冲策略
- 压缩和索引技术提高检索性能
## 实际案例:推动实时分析的成功实践
一个成功的案例是某社交媒体公司通过改进网络流量分析,实现了实时广告检查和用户体验优化。他们部署了一套基于Apache Kafka和机器学习的流处理系统,能在数据生成不到一秒钟后反馈分析结果。这不仅提高了系统响应速度,同时增强了用户体验和平台安全性。
## 未来展望
面对大规模网络日益增多的流量分析需求,未来我们可能会看到更多先进技术被应用于此领域。这包括更智能的人工智能模型、更快的硬件设备(如基于FPGA的加速器),以及Qvased质子流计算等前沿技术。
综上所述,尽管目前大规模网络中流量分析的实时性面临着挑战,但通过上述技术和方法,我们能够制定出切实可行的解决方案,以改善现状,提升实时性水平。
阅读这篇文章的您,如果是网络管理员、信息安全专家或对网络流量分析感兴趣的读者,希望本文能够在您的工作中提供帮助和启发。我们的最终目标是不断提升网络服务的质量和安全,为用户提供更加流畅的互联网体验。