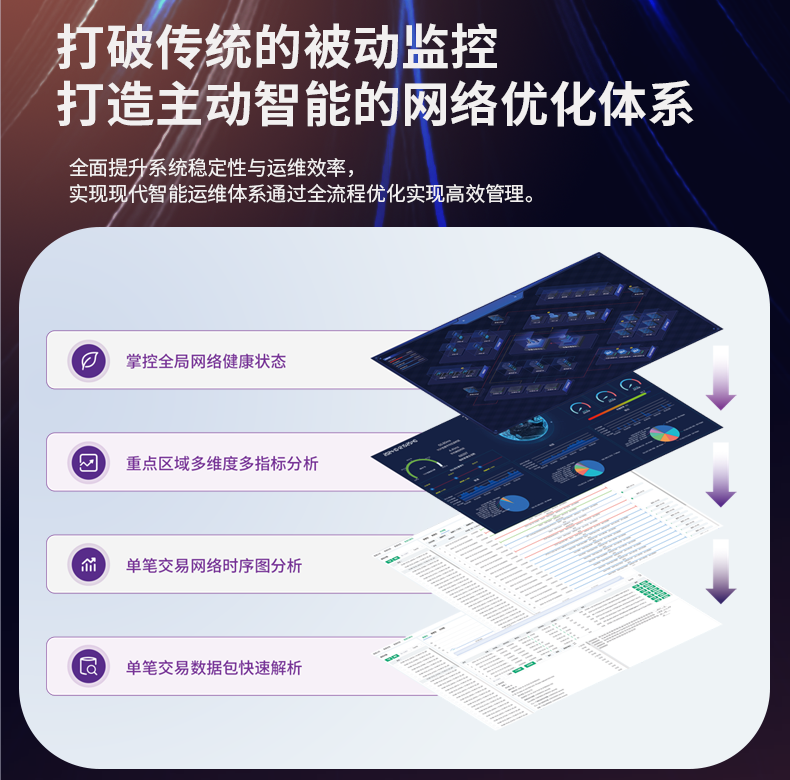
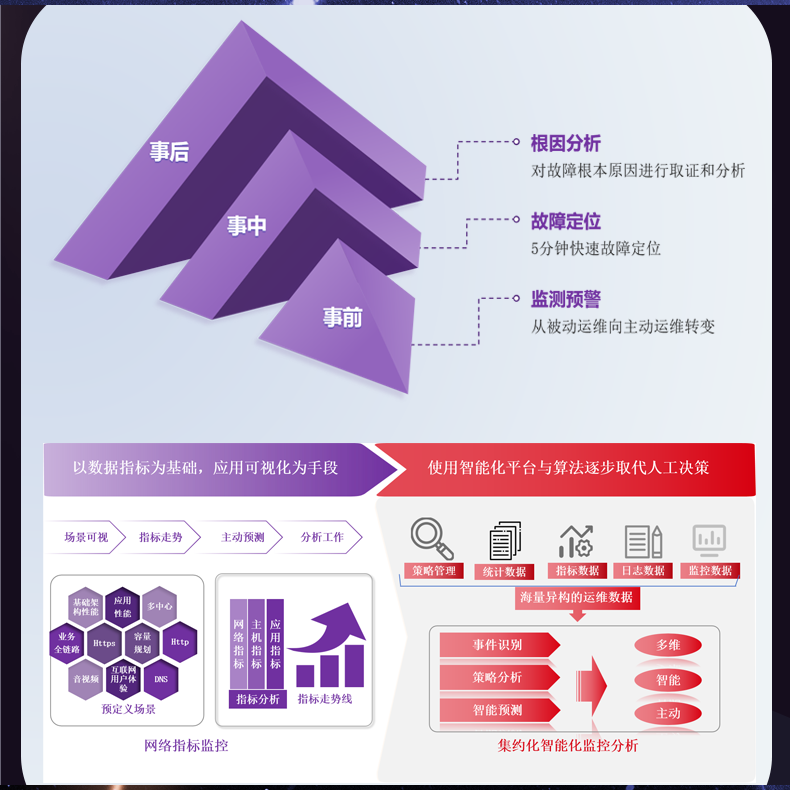
# 流量日志的存储和审计能力无法支持大规模企业环境
在当今快速发展的数字化时代,企业的网络流量日益增多,随之而来的流量日志的存储和审计需求也愈发复杂。随着企业规模的扩大,以往的日志处理方式显得捉襟见肘,难以满足现代大规模企业的需要。这篇文章将深入探讨流量日志存储和审计在大规模企业环境中的挑战,并提出切实可行的解决方案。
## 一、流量日志的核心问题
### 1.1 数据量巨大
在大规模企业中,每时每刻产生的网络流量都可用“海量”来形容。这些流量数据在原始状态下是无结构的,它们既包括合法合规的业务流量,也涵盖可能构成安全威胁的异常流量。传统的存储解决方案往往无法高效地管理如此庞大的数据量。
### 1.2 多样性和复杂性
流量日志中包含多种协议的沟通记录,例如HTTP、SMTP、FTP等,每种协议的数据格式各不相同,这增加了解析和存储的复杂性。此外,不同的业务部门可能会生成不同类型的数据日志,这要求系统具备强大的适应能力。
### 1.3 审计和合规要求
随着企业规模的扩大,审计和合规需求越来越严格。企业必须遵循一定的法律法规对流量日志进行审计,并及时发现和处理异常活动。这对流量日志的即时性和易用性提出了高要求。
## 二、传统解决方案的不足
### 2.1 存储成本高昂
传统存储方式通常依赖物理存储设备,无论是磁盘阵列还是网络存储,这些设备的采购、维护和扩容都成本高昂,难以灵活应对数据量的爆炸式增长。
### 2.2 缺乏实时分析能力
传统的批处理系统常常失去数据的实时性,无法快速有效地分析和响应潜在的威胁,导致安全事件的处置滞后。
### 2.3 系统扩展性差
很多企业使用的日志管理系统在设计上并未考虑到大规模数据处理的需要,因而在性能和扩展性上存在明显瓶颈,无法在企业成长过程中有效支持业务需求。
## 三、现代化解决方案探索
### 3.1 大数据技术
#### 3.1.1 Hadoop和Spark
利用Hadoop和Spark等大数据技术,可以有效地对流量日志进行分布式存储与处理,这类系统可以水平扩展,以支持数据量的动态增长。同时,Spark的内存计算能力能够支持流量日志的实时分析。
#### 3.1.2 Apache Kafka
作为一款高吞吐量的分布式消息队列系统,Kafka能够在日志数据的采集和传输过程中提供高效、可靠的支持,确保数据在大流量环境下的有序处理。
### 3.2 云存储和计算
#### 3.2.1 云原生架构
借助云存储技术,如AWS S3、Azure Blob Storage等,可以动态适应存储需求的变化,规避物理设备的局限性。同时,结合云计算资源,可以按需扩展计算能力,优化成本和性能。
#### 3.2.2 无服务器计算
使用无服务器架构(Serverless),如AWS Lambda或Azure Functions,可以在需要处理流量日志时动态分配计算资源,不再依赖于物理服务器的配置,灵活性大幅提升。
### 3.3 机器学习与AI
通过实施机器学习和AI技术,可以实现对流量日志的智能分析和异常检测。这不仅改进了威胁检测的准确性,还能够减轻安全分析人员的负担。
## 四、案例研究
### 4.1 全球科技公司案例
一家全球领先的科技公司在其海量数据处理挑战中,采用了基于Hadoop的大数据平台,结合Kafka进行实时数据流处理,克服了传统存储方案的阻碍,成功实现了高效的日志处理和分析。
### 4.2 通信企业案例
某大型通信企业通过部署云原生架构,利用云计算的灵活性,显著降低了流量日志存储和处理的成本。结合AI分析模型,他们的安全事件响应时间缩短了50%。
## 五、实施建议
### 5.1 评估现有基础设施
企业应首先评估现有的IT基础设施,明确痛点和瓶颈,再根据业务需求和规模设计适合的日志管理方案。
### 5.2 选择合适的工具和技术
结合企业实际,与业务增长目标相匹配,选择适合的大数据技术、云服务解决方案以及AI工具,确保技术资源的投资效益最大化。
### 5.3 持续优化和监控
构建完善的监控机制,对流量日志的处理过程进行持续优化,并根据变化的业务需求和环境,动态调整相应的策略。
## 六、结论
大规模企业中的流量日志管理是一项复杂但至关重要的任务。通过现代化的解决方案,将大数据分析、云计算和AI技术相结合,可以有效应对当前和未来的挑战。企业应持续关注技术进步,并灵活调整自身策略,以实现流量日志管理的最佳实践,从而保护企业的网络安全和业务持续发展。
随着技术的不断进步,未来的流量日志管理将在移动性和智能化方面朝着更高效的方向发展,为企业的数字化转型提供坚实的基础支撑。