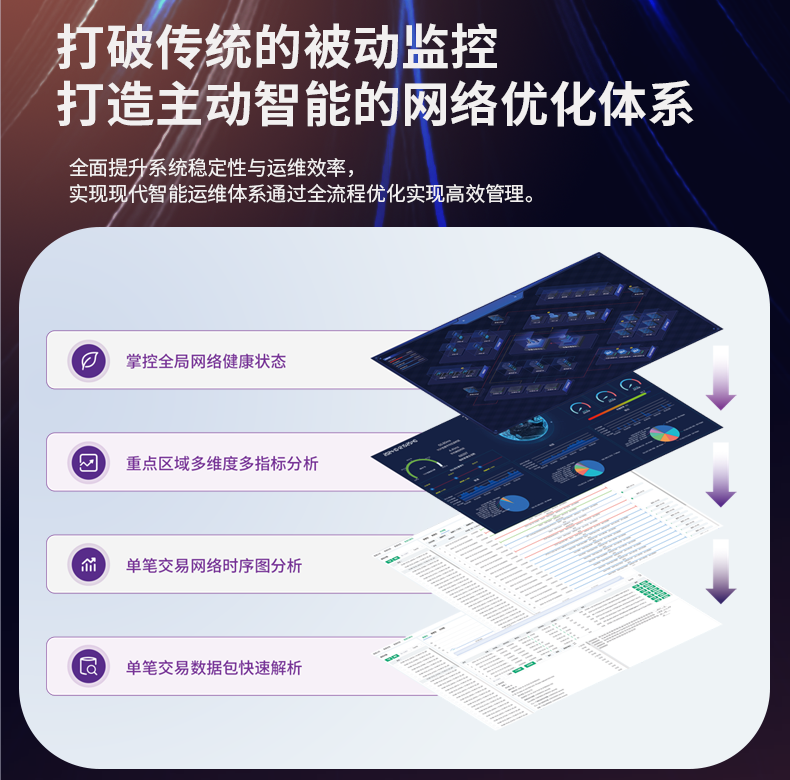
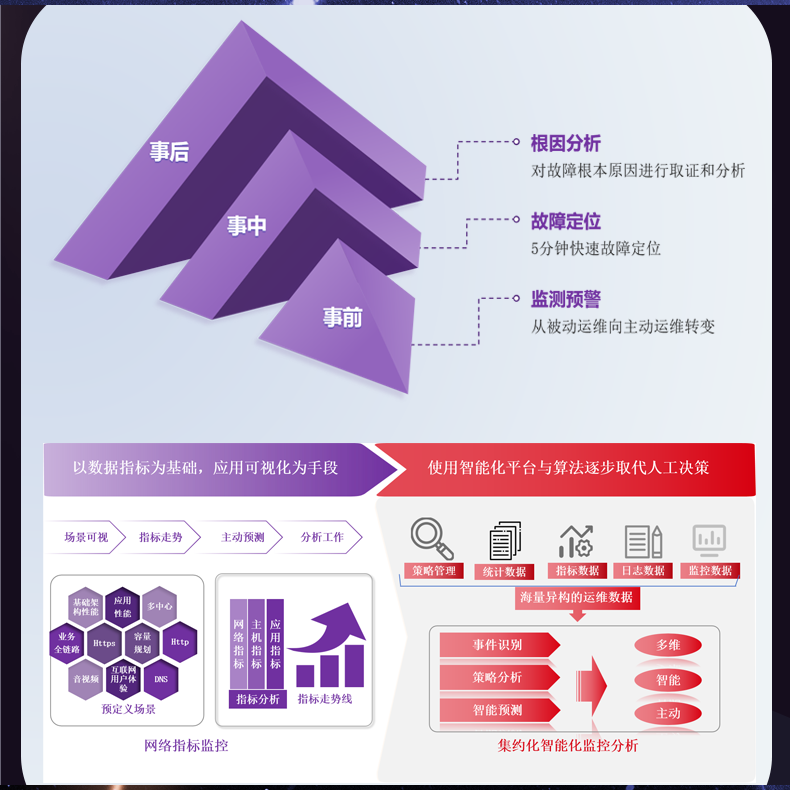
# 流量分析工具对高吞吐量数据的处理能力不足
在现代数字化时代,数据是商业和技术决策的核心基础。流量分析工具被广泛应用于从实时市场分析到网络流量监控的各种领域。然而,当面对高吞吐量数据时,即巨大的数据流量和实时需求,这些工具显然表现出了处理能力的瓶颈。这篇文章将深入探讨流量分析工具在处理高吞吐量数据时遇到的挑战,并提出可行的解决方案。
## 流量分析工具的现状
### 什么是流量分析工具?
流量分析工具用于收集、存储、分析网络和应用程序流量,以便管理者和团队成员可以做出明智的决策。其功能包括监视流量模式、检测异常行为、优化网络性能以及数据可视化。然而,随着数据量的爆炸性增长,许多工具在处理高吞吐量数据时逐步显现出限制。
### 当前工具的局限性
1. **数据输入的限制**:
- 大多数流量分析工具依赖于传统的数据输入架构,例如依靠单个服务器或简单的集群。这种架构在处理大量并发的数据请求时容易导致瓶颈。
2. **存储和检索效率**:
- 工具通常存在存储效率低下的问题。即便在引入分布式数据库后,存储和检索大量数据仍然需要高效的算法,而这些工具在这方面往往不够完美。
3. **实时分析能力差**:
- 高吞吐量数据要求实时处理能力。然而,许多现有工具在实时分析上的处理速度不够快,导致数据分析滞后于实际情况。
## 高吞吐量数据的挑战
### 数据量的挑战
高吞吐量数据的核心挑战在于数据量通常是巨大的,并且以复杂的方式不断变化。这要求工具能够快速地适应,处理和分析数据,以确保高效地从中提取洞察。
### 实时性和准确性的挑战
实时性是关键,因为数据通常用于立即决策,而延迟可能导致重大损失。此外,尽管速度很重要,准确性在流量分析中也是至关重要的因素,因为错误的数据可能误导决策。
### 异构数据整合的挑战
高吞吐量数据通常是异构的,来源于不同类型的设备和平台。这要求工具能够无缝整合多个数据源,跨越设备和协议,以完整地描绘数据画像。
## 面对不足的解决方案
### 强化数据架构
1. **引入可扩展的分布式架构**:
- 利用现代云技术和分布式数据库,如Apache Hadoop和Spark,实现数据处理的弹性扩展和分布式计算。
2. **采用更强大的数据缓存与索引机制**:
- 使用先进的缓存系统(如Redis)和索引技术(如Elasticsearch),提高数据的存储和检索效率。
### 提升实时分析能力
1. **实时流处理框架**:
- 采用流处理框架,如Apache Kafka和Apache Flink,能够处理实时数据传输,加速分析过程。
2. **提高算法的效率**:
- 开发和使用专为高效处理大数据设计的算法,例如在数据压缩和过滤上使用机器学习方法,以减少数据噪声,提高分析速度。
### 数据整合技术的进步
1. **实施数据中台**:
- 建立统一的数据中台,整合多种数据源,标准化数据格式,使分析工具可以高效地处理和分析。
2. **支持多协议和设备兼容**:
- 开发兼容多种协议和设备的接口,借助API和SDK简化数据的集成过程。
## 前景和挑战的展望
在高吞吐量数据处理领域持续创新是必然的趋势。展望未来,我们可以期待流量分析工具在技术和商业应用上的进步:
- **人工智能的深度应用**:
- 流量分析工具将越来越多地采用人工智能进行自动化分析,预测模式和异常检测。
- **可视化和决策分析扩展**:
- 提供更强大的可视化工具,以便用户能够更直观地理解和操作数据。
- **增强安全性的解决方案**:
- 随着数据的增加,安全性问题也随之而来,流量分析工具将提升其在数据保护方面的内置解决方案。
## 结论
流量分析工具在应对高吞吐量数据方面存在多重不足。这些不足源于数据架构、实时性、异构整合的多个挑战。然而,通过现代技术的应用和创新解决方案,可以有效地增强工具的性能。技术和市场的动态发展要求不断改进工具,以满足当前及未来的数据处理需求。随着工具的不断进步,企业和技术团队将能够更好地处理复杂的数据流,为决策提供稳定的支持。