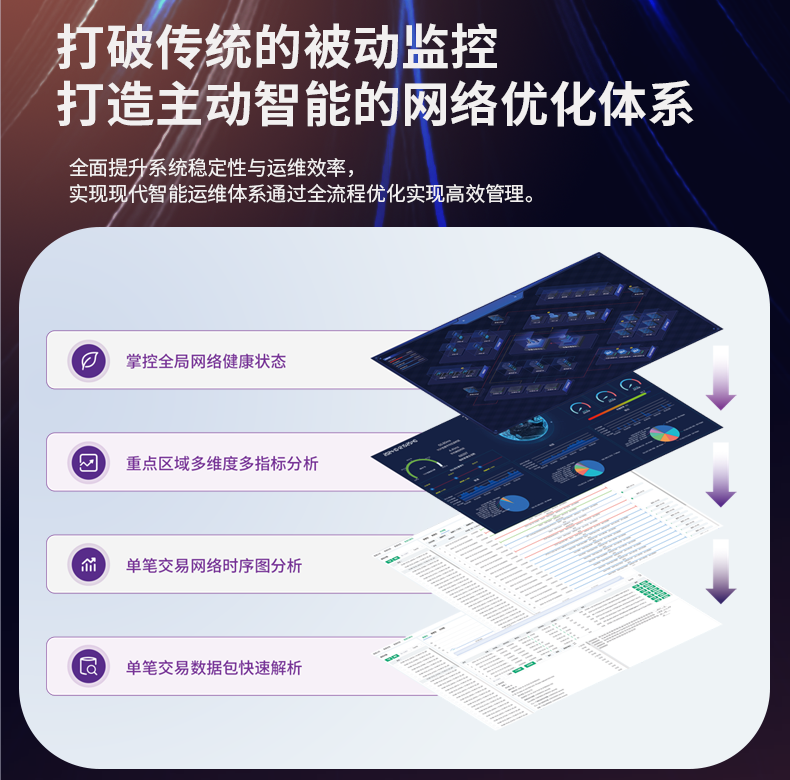
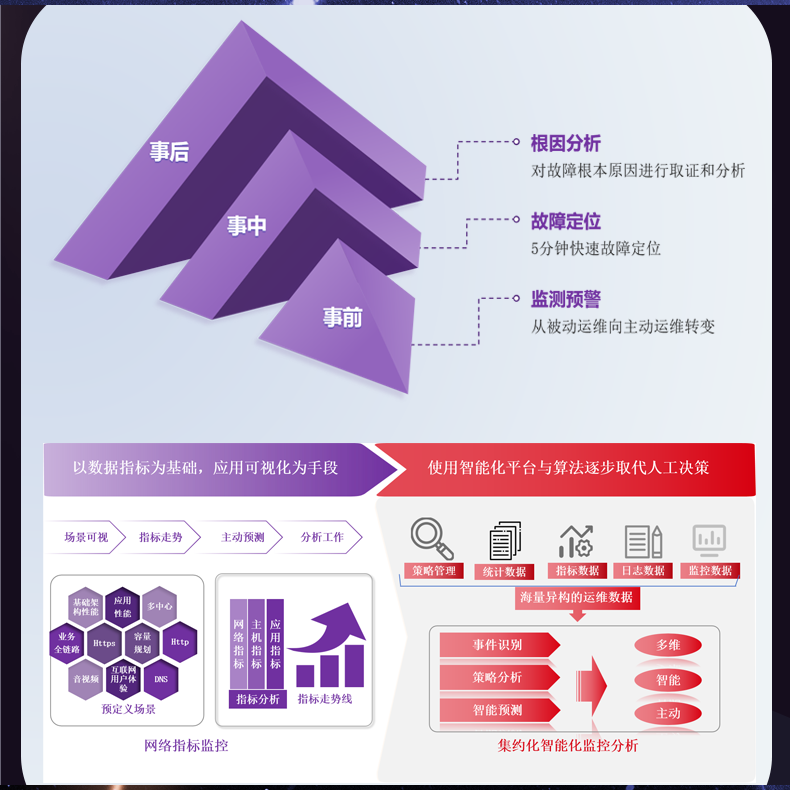
# 流量日志的分析工具未能实时处理大规模数据
随着互联网的发展和企业对数据分析的需求激增,流量日志已经成为企业获取用户行为和系统性能信息的重要来源。然而,在面对大规模数据时,许多分析工具面临着实时处理的挑战。本文将详细探讨这一问题,并提出有效的解决方案。
## 引言
### 大数据时代的挑战
在大数据时代,企业需要处理的数据量呈爆炸式增长。网站、应用程序和物联网设备产生的流量日志数据每日以TB甚至PB为单位增长。这些数据不仅在数量上庞大,而且在形式上多样,包括文本、图像、视频和传感器数据。
### 流量日志的重要性
流量日志包含用户请求、响应时间、点击路径、错误信息等关键信息,能够帮助企业优化网站性能、提高用户体验、实施精准营销和预防安全威胁。因此,实时处理流量日志对于企业智能决策和及时响应至关重要。
## 问题分析
### 现有工具的局限性
许多现有的分析工具在处理小规模数据时表现良好,但随着数据量的增加,这些工具往往暴露出以下问题:
1. **容量限制**:许多工具设计之初并未考虑到今日巨大的数据量,导致在实际使用中容易出现拥堵,无法及时处理所有数据。
2. **计算资源不足**:实时处理大规模数据需要强大的计算资源,现有工具在资源分配上难以支持,往往导致系统响应缓慢。
3. **存储性能瓶颈**:流量日志的存储和读取速度直接影响数据处理的效率,许多工具在存储性能上未能充分优化。
4. **架构不灵活**:许多工具使用固定架构,难以根据需求动态扩展,限制了处理能力的提升。
### 实时处理的复杂性
实时处理不仅要求速度,还要求准确性和稳定性。要实现实时处理,系统必须能迅速处理海量数据,同时确保信息的准确传输和分析。这对于硬件、软件和网络资源的综合管理提出了极高的要求。
## 解决方案
### 分布式计算和存储
#### 技术概述
分布式计算和存储技术可以有效解决容量和存储性能瓶颈。通过将数据和计算任务分散到多台服务器上,分布式系统可以显著提升处理速度和效率。
#### 实施步骤
1. **采用Hadoop**:利用Hadoop框架进行分布式存储和计算,能够处理和存储极大规模的数据集。
2. **使用Spark**:Spark能够处理实时数据流,支持流式计算,适合需要快速处理的数据环境。
3. **云计算资源的集成**:整合AWS、Azure等云服务资源,支持动态扩展和资源调度,增强处理灵活性。
### 数据预处理优化
#### 技术概述
对流量日志进行预处理可以有效降低系统的负担,提高处理效率。数据预处理包括数据清洗、格式转换和冗余数据删除等。
#### 实施步骤
1. **数据清洗**:通过自动化工具去除不必要的数据,如重复日志、损坏记录。
2. **格式转换**:将日志转化为易于分析的格式,如JSON或Avro,以减轻系统负担。
3. **索引和压缩**:通过建立索引和数据压缩,加快数据查询速度,减少存储空间。
### 架构改进
#### 技术概述
现代化的架构设计可以提高系统的处理能力和适应能力。通过微服务架构,系统能够根据需求动态调整。
#### 实施步骤
1. **微服务架构**:拆分现有工具,将各功能模块化为独立服务,支持按需扩展和维护。
2. **容器化技术**:使用Docker和Kubernetes等技术实现服务的容器化部署,确保高效管理和灵活扩展。
3. **事件驱动模型**:引入Kafka或RabbitMQ,支持实时事件流处理,提高响应速度。
### 人工智能辅助
#### 技术概述
人工智能在数据分析中的应用,可以显著提高信息处理的Speed和准确性。
#### 实施步骤
1. **AI模型优化**:通过训练机器学习模型,从流量日志中提取复杂模式和预测趋势。
2. **自动异常检测**:实施AI算法对异常流量进行自动检测和报警,减少人工监测负担。
3. **智能决策支持**:利用AI生成实时决策建议,帮助企业快速应对变化和挑战。
## 结论
面对流量日志的实时处理挑战,企业需不懈努力,探求优化方案。这包括技术实现和架构改进,以及对新技术的积极探索和应用。分布式计算、数据预处理、架构现代化和人工智能应用构成了全面解决方案的基础。在这一领域的持续创新,将确保企业能够在大数据时代保持竞争优势。
通过深入探讨和解决方案的全面实施,企业将能够克服流量日志分析工具面临的挑战,实现实时处理大规模数据的愿景。如果能够灵活运用上述技术和策略,流量日志分析将不再是难以攀登的高峰,而是企业智能化转型的强大支持。