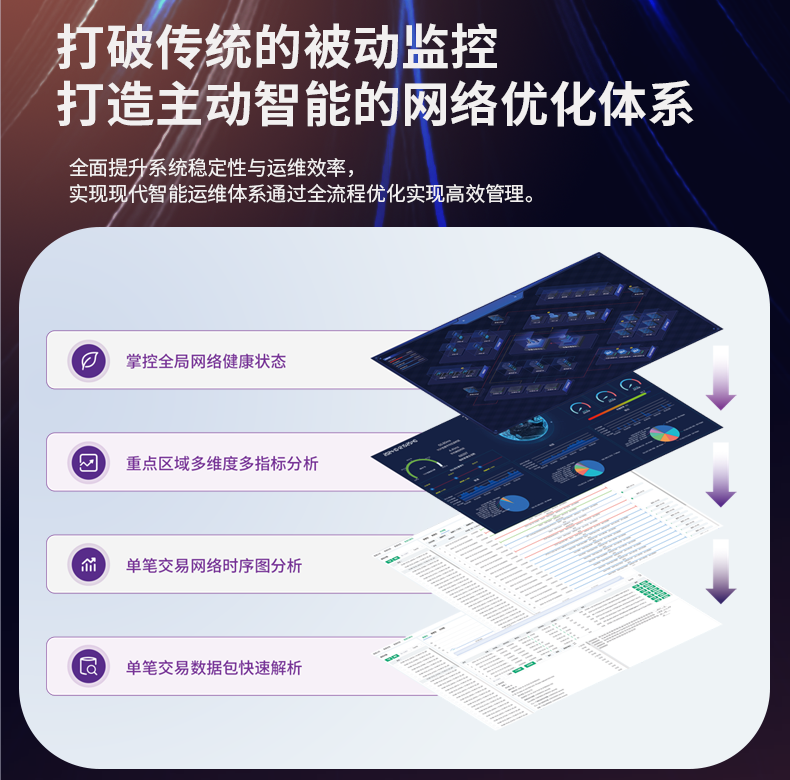
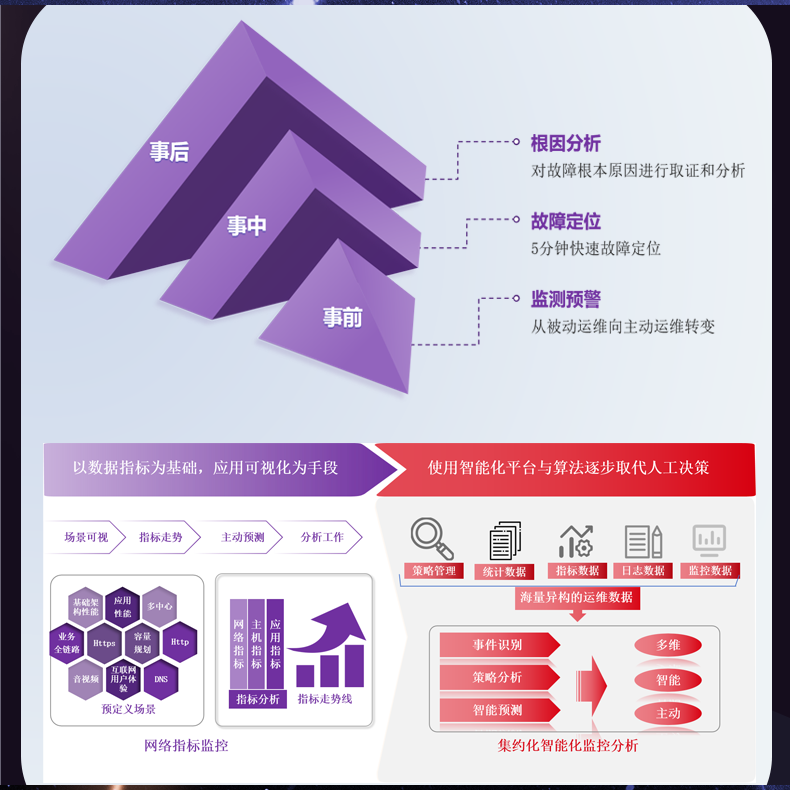
# 流量日志的存储和分析性能无法应对大规模企业需求
在数字化转型的浪潮下,各行各业都逐步向数字化、信息化转型,这使得企业的数据量呈指数级增长。尤其是流量日志的数据,常常以分、秒为单位产生并积累,这就给企业的存储和分析性能带来了严峻挑战。如果不加以妥善处理,会制约企业的发展。本文将详细分析流量日志面临的存储和分析问题,并提出可行的解决方案。
## 一、流量日志面临的现状与挑战
### 1.1 数据洪流带来的存储压力
随着互联网应用的普及和企业规模的扩大,流量日志的产生已经超出了传统存储系统的承载能力。企业需要存储大量的日志数据,以便于后续的分析和安全审计。例如,电子商务网站需要不仅要存储1年的访问日志以备分析,同时需要应对双11等大流量场景。
### 1.2 实时性与分析深度的矛盾
企业需要对流量日志进行实时分析,以迅速做出业务决策。然而,庞大的数据量和复杂的分析计算往往导致延迟,无法及时响应市场变化。例如,流量日志分析的滞后可能导致网络攻击检测的失败,给企业带来巨大的风险。
### 1.3 不同数据源间的整合
企业的流量日志通常来自不同的网络设备和应用,这些数据格式不同,频率不一,如何进行有效整合以支持全貌式的分析是一个重要挑战。
## 二、解决方案分析与优化策略
### 2.1 分布式存储系统的引入
为应对存储挑战,企业可以引入分布式存储系统,如Hadoop HDFS、Amazon S3等。这些系统通过分布式架构实现高效的读写操作,并支持水平扩展以适应增长的数据需求。
#### 2.1.1 HDFS的高效存储能力
HDFS 是 Hadoop 分布式文件系统的基础,分析大规模数据集时常常使用。它通过将数据分块存储在不同的节点上,并配有冗余备份来保证数据的安全性和可用性。
#### 2.1.2 S3 的存储与备份
Amazon S3 提供了极高的可扩展性和耐久性,只需按需付费,特别适合中小企业灵活使用。它还与许多数据分析工具兼容,支持复杂的日志分析需求。
### 2.2 大数据分析架构的应用
传统的数据分析方法已经不能满足实时性和大规模数据处理的需求,企业可以借助大数据处理工具和框架,如Apache Spark和Flink,从而提升分析性能。
#### 2.2.1 Apache Spark的速度与灵活性
Apache Spark 是一个用于大规模数据处理的快速、通用的计算引擎。它支持内存中计算以及批处理和流处理的混合工作负载,从而实现对流量日志的近实时分析。
#### 2.2.2 Flink 提供实时流处理
Apache Flink 是一个用于流式数据处理的分布式处理引擎,支持高吞吐量、低延迟的流处理。它非常适合处理企业级流量日志数据,从而即时生成有价值的洞察。
### 2.3 数据整合与标准化工具
实现不同来源数据的整合与标准化是流量日志分析的基础。企业可以采用诸如Apache Nifi、Kafka Connect等数据整合工具,与ETL(Extract, Transform, Load)解决方案结合使用,确保数据输入的标准化和一致性。
#### 2.3.1 Apache Nifi对数据流的控制
Nifi 提供了全面的数据流管理能力,简化了数据流动、转换,并在企业级环境中提供实时的综合数据处理、路由和监控。
#### 2.3.2 Kafka Connect的扩展性
Kafka Connect 提供了用于连接Kafka与外部系统的组件,允许数据无缝地从源系统移入或移出,并能在多种平台之间提供一致性数据管道。
## 三、实施案例分析
我们以某大型电商平台为例,该平台在采用上述技术后,实现了有效的日志存储和分析优化:
1. 在分布式存储方面,采用Amazon S3结合Glacier进行冷热数据分离,保证高效存储与成本的合理控制。
2. 在数据分析层,使用Apache Flink配合Kafka的流处理方案,大幅度提升了订单、用户行为的实时分析能力。
3. 数据整合领域,利用Nifi保证来自多种设备和应用的流量日志的格式统一与标准化,最终实现一种从数据采集到数据分析的流畅体验。
## 四、总结与展望
随着企业数据的不断膨胀,流量日志的存储和分析将面临持续的挑战。但以上列举的解决方案,可以在不同程度上缓解这些问题,使得企业能够不仅存储并分析庞大数据量,也能从中提取有价值的信息,为企业决策与业务发展提供助力。
未来,随着技术的更迭与进步,我们有理由相信,流量日志的存储与分析会越来越智能化、自动化,进一步助力企业在信息时代的壮大与成功。