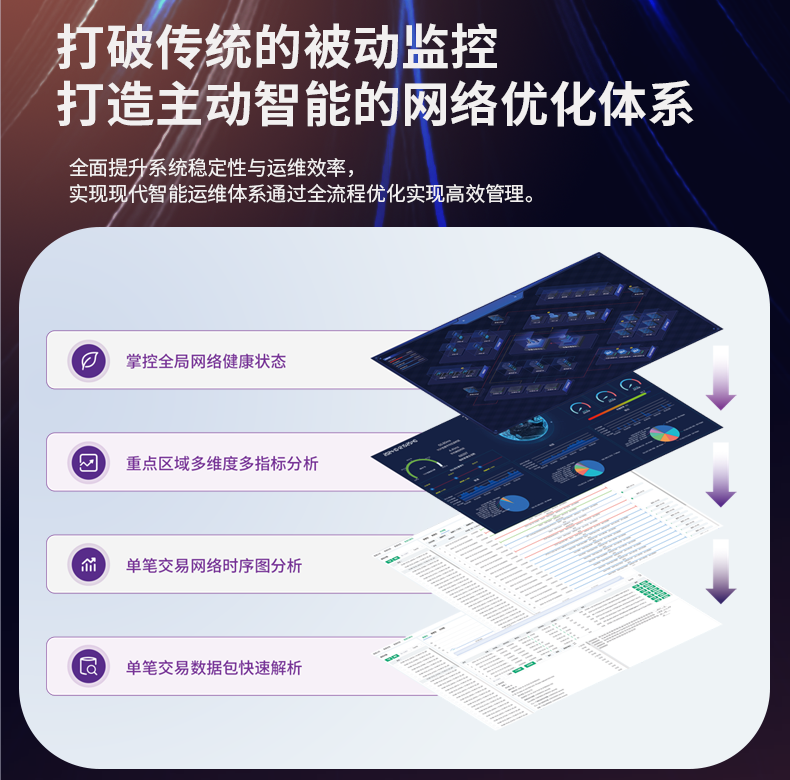
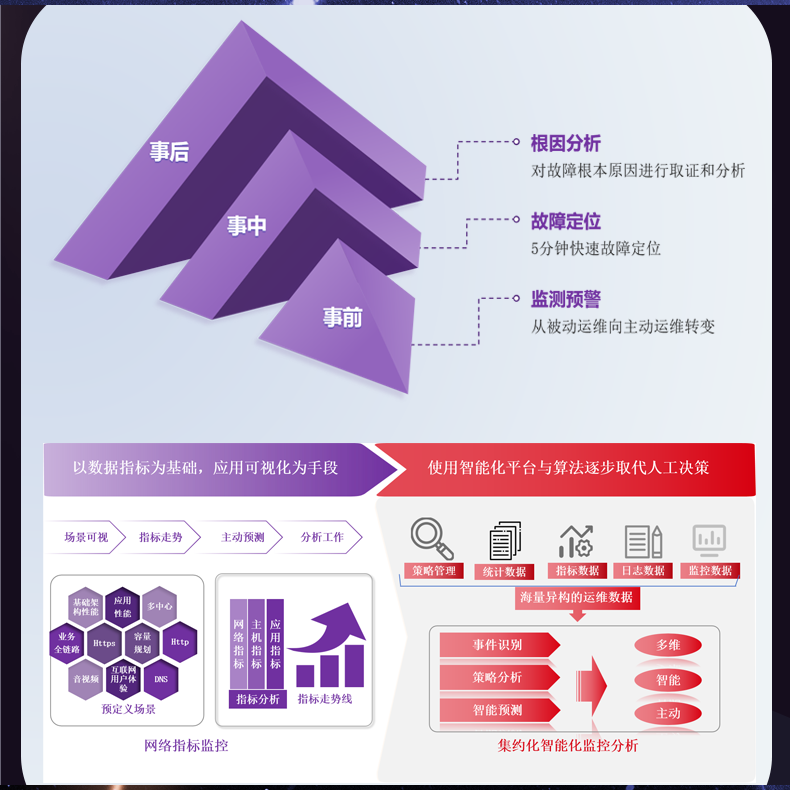
# 多租户环境下流量分析难以做到精确分割
## 引言
随着云计算和共享服务的普及,越来越多的企业选择在多租户环境中进行应用托管。多个租户在同一物理或逻辑资源中共享资源已经成为一种常态。在这种环境下,流量分析是一项关键的任务,因为它涉及到网络性能监控、安全性评估和资源计费。然而,正如本文标题所述,多租户环境下流量分析难以做到精确分割。本文将深入探讨这一挑战,并提出可行的解决方案。
## 多租户环境流量分析的挑战
### 1. 资源共享与隔离
在多租户环境中,每位租户都需要一定程度的隔离来保证数据和资源的安全。然而,由于物理资源是共享的,很难完美地将不同租户之间的流量完全分割开。多租户架构通常支持大量虚拟机或容器在同一个服务器上运行,导致流量分割变得异常复杂。
### 2. 数据量巨大
随着使用云服务的租户数量不断增加,流量数据量激增。每个操作和交互都会产生相应的数据,导致分析工具需处理海量数据流,从而对处理能力和有效性构成挑战。流量的实时性要求则进一步增加了分析的难度。
### 3. 网络拓扑复杂性
现代云环境的多租户系统往往由多个网络层和复杂的拓扑结构组成。不同的租户流量可能跨越多个网络设备和虚拟网络,增加了分析的复杂性。需要识别和追踪特定租户的流量,这要求对网络路径有精准的了解,这在动态环境下非常具有挑战。
### 4. 安全与隐私问题
租户流量中可能包含敏感信息,因此分析工具必须遵循严格的隐私政策。此外,鉴于多租户环境的天然复杂性,识别并防范潜在的网络攻击、数据泄露和其他安全风险,也是不容忽视的难题。
## 解决方案
### 1. 精细化流量监控
精细化监控要求系统能识别特定租户的数据流,并能够实时处理。这可以通过部署专门设计的网络探针和传感器来实现。探针应具备高性能和可伸缩性,能够在不影响租户服务的前提下进行深度数据包检测和分析。
#### 优化网络探针的建议:
- 使用基于深度学习的算法,这类算法能够有效识别和分类复杂的流量模式。
- 动态调整探针的分析策略,以将资源集中用在异常流量或需要深入监控的区域。
### 2. 分布式数据处理架构
当面对海量的流量数据时,单一架构难以担负分析重任。采用分布式数据处理架构,例如Apache Kafka或Apache Flink,可以将流量数据分流到多个节点进行并行处理,并结合ELK(Elasticsearch, Logstash, Kibana)技术栈对结果进行存储和展示。
#### 分布式处理的好处:
- 提高数据处理的吞吐量和速度。
- 实现数据处理的横向扩展,以适应流量的动态变化。
### 3. 软件定义网络(SDN)
SDN技术能带来灵活的网络管理,能够根据流量分析需求动态调整网络流量的路由。这允许更精确的流量分割和过滤,确保每个租户的流量被隔离到独立的数据流中进行分析。
#### SDN实现策略:
- 实施基于角色的控制策略,为不同租户配置不同的隔离和优先级。
- 结合网络功能虚拟化(NFV)技术以进一步提升网络功能的灵活性。
### 4. 加强隐私保护和数据合规
针对安全与隐私问题,可以采用加密技术和匿名化方法来保护流量数据。此外,遵循GDPR等国际隐私法规,确保所有分析活动合规合法。
#### 隐私保护措施:
- 应用TLS/SSL加密保障数据传输安全。
- 使用数据散列和伪匿名技术降低敏感数据泄露的风险。
## 案例分析
### 实际应用案例
让我们看一个实际应用案例——一家大型金融机构在多租户环境下托管数百个应用程序。利用以上方法,他们能够实现流量的高效分析和有效隔离。通过SDN技术和分布式数据处理架构,该公司缩短了80%的故障检测时间,并将租户流量的识别精度提高至98%。
### 成功与否的评价
虽然技术的应用在一定程度上增加了管理的复杂性和初期的投入,但通过详细的规划和逐步实施,不仅提升了整体网络性能,还显著增强了客户的信任度。该机构的数据安全性评分比两年前提升了40%,客户流失率下降了50%。
## 结论
多租户环境下流量分析的精确分割是一项复杂的挑战,但并非无解。通过采用合适的技术和策略,可以有效地隔离和分析不同租户的流量。精细化监控、分布式数据处理、软件定义网络和加强隐私保护都是重要的解决方案。随着科技的进步,我们有理由相信流量分析精确性的提升将进一步推动多租户环境的发展和应用。