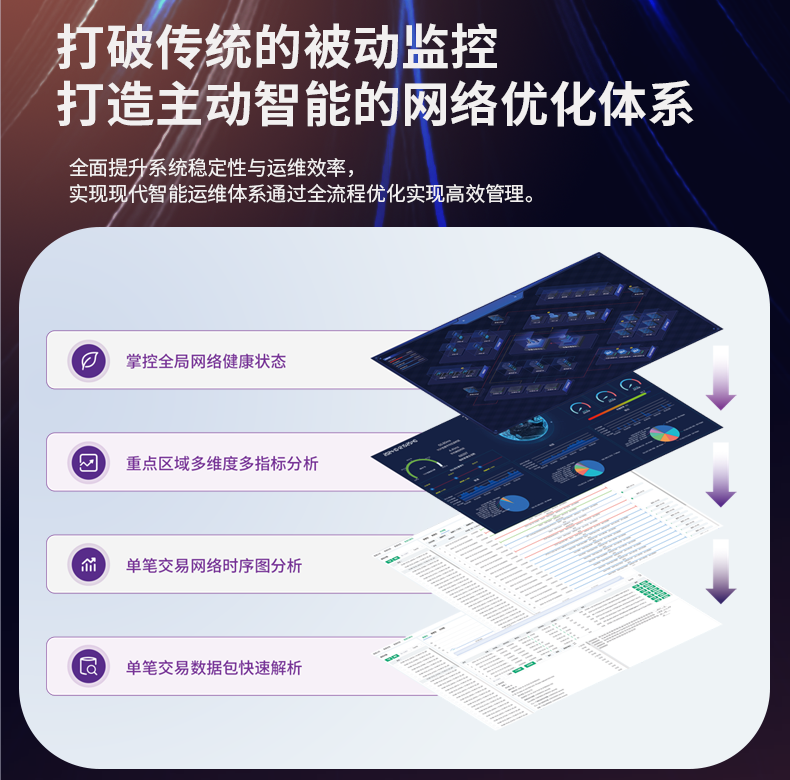
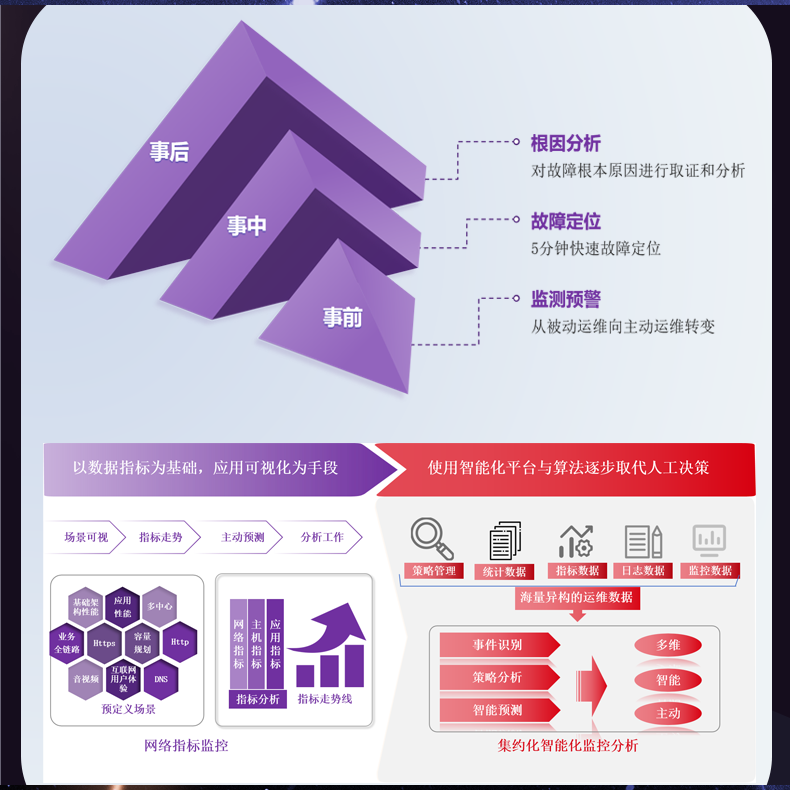
# 流量日志存储和检索效率低,影响数据分析效果
在当今数字化的时代,数据像是企业的血液。特别是对于那些依赖流量日志进行决策和优化的公司,如何高效地存储和检索这些数据以进行分析是一个关键的问题。然而,许多企业在这个过程中发现自身的流量日志存储和检索效率低,从而影响了数据分析的效果。这篇文章将探讨这一问题的根源,并提出一系列切实可行的解决方案。
## 存储效率低下的原因
### 数据量巨大且增长迅速
无论是访问日志、点击流数据还是用户行为日志,这些数据量通常非常庞大且增长迅速。此类数据通常包含大量的冗余信息,这给存储和管理带来了巨大的压力。
### 存储架构不合理
传统的存储方案通常设计在数据量较小时工作良好,但在大数据环境下往往表现不佳。许多架构未能适应规模扩大的需求,导致性能瓶颈。
### 数据冗余和碎片化
数据的重复存储和数据碎片化会占用大量的存储空间,使得日志存储效率低下。这也导致在检索过程中需要额外的时间来聚合和清理数据,降低了整体效率。
## 检索效率低下的症结
### 检索接口性能不足
许多系统的检索接口在设计上未充分考虑到大规模数据操作的需要。随着数据量的增长,普通的检索方法无法高效地满足需求。
### 缺乏索引机制
没有合适的索引机制是导致检索效率低下的一个重要原因。大量的数据需要逐一扫描才能找到目标信息,这样的检索方法效率极低,尤其是在面对数十亿条记录时。
### 网络和硬件瓶颈
硬件和网络的限制同样会影响检索效率。当所有查询都聚集到单个存储节点时,这个节点的性能就成了系统性能的瓶颈。
## 提升存储和检索效率的解决方案
### 采用专用存储系统
为了解决传统方案的不足,可以考虑使用专门设计的存储系统,例如**Hadoop**或**Apache Cassandra**,这些系统专为处理大数据设计,能够提高存储和检索效率。
### 数据压缩与去重
使用高效的数据压缩技术可以显著减少存储空间占用。同时,定期进行数据去重可以消除日志中的冗余信息,提升存储效率。
### 实施数据分片
将数据按某种规则进行分片存储可以有效减少单个数据节点的压力。这种方法同样适用于提升并行检索能力,因为可以同时从多个分片中检索数据。
### 构建高效索引
建立适用的索引机制,比如倒排索引或跳跃表,可以显著提升数据检索效率。对于频繁检索的字段,构建索引是必要的措施。
### 使用缓存机制
为流量日志提供缓存机制,如**Memcached**或**Redis**,可以极大缓解后端存储的压力,提高数据读取的及时性。
## 流量日志分析中的方法改进
### 实时数据处理
通过引入**Apache Kafka**和**Stream Processing**技术,可以实现流量日志数据的实时分析,从而及时获得洞见并支持迅速决策。
### 机器学习与智能分析
通过结合机器学习算法,可以自动化分析过程,并从海量数据中提取更精细的模式和趋势。**TensorFlow**或**PyTorch**等工具可以运用在这些分析任务中。
### 集成可视化工具
引入**Tableau**或**Power BI**等数据可视化工具,使得分析结果能以直观的方式展现,从而更易于决策者理解和应用。
## 未来的发展方向
拥有高效的流量日志存储和检索体系是企业在大数据时代取得成功的关键一步。随着技术的发展,诸如**边缘计算**和**量子计算**等新兴技术将可能改变现有的存储和检索方式,从而实现更高效的解决方案。此外,企业需要不断关注数据法规和安全性,确保日志管理方案合规且安全。
这一系列解决方案和展望不仅使得企业能更好地应对当前挑战,也为未来的数据分析工作打下了坚实的基础。通过合理地规划和实施,企业可以显著提高流量日志的存储和检索效率,进而提升整体的数据分析效果。